- ABOUT GSI
- AI
- HPC
- INDUSTRIES
- AEROSPACE & DEFENSE
- MEMORY
- RESOURCES
- INDEPTH
-
-
AI’s Energy Dilemma

-
-
- INTEGRATORS
-
- TOOLS
-
- INDEPTH


Home Wayfair’s Visual Search and the Latest in Similarity Search Research
Author: Pat Lasserre
Visual search is a rapidly emerging trend that is ideal for retail segments, such as fashion and home design, because they are largely driven by visual content, and style is often difficult to describe using text search alone.
Wayfair is an example of a home design company in the retail segment that makes it easy for you to search their catalog using visual search. As seen in figure 1 below, their Visual Search tool lets customers use pictures of furniture they like to find visually similar items or affordable alternatives on the Wayfair website.
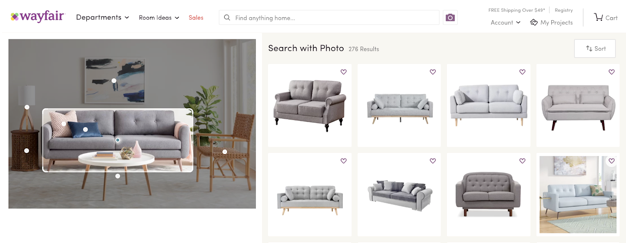
Figure 1: Searching for similar items on the Wayfair website.
In this blog post we will briefly highlight how Wayfair uses visual search to improve the online retail experience and we will also touch upon some of the latest research in similarity search.
When a picture is presented to Wayfair’s Visual Search tool, an embedding is created for the picture that maps the image into a multi-dimensional vector space. Visually similar products are mapped closer together in this space, and dissimilar products are mapped further apart.
One of Wayfair’s advantages in the furnishings market is its large furniture and décor dataset that they use to train this embedded vector space. This large dataset allows for more specific and accurate model training.
Wayfair performs a k-Nearest Neighbor (k-NN) similarity search between the embedded vector of the uploaded query image and the embedded vectors of the products in their catalog to find visually similar images to the picture. Visual Search then recommends the products with the closest embeddings to the picture’s embedding.
As part of the algorithm that searches for neighbors, Wayfair uses Hierarchical Navigable Small World Graphs that are highly connected. Nodes in the graph are images and edges connect similar images in the graph. The graph structure ensures that any node in the graph can be reached in a small number of hops from any other node.
Wayfair states that the hierarchy of small world graphs allows them to “search the space for nearest neighbors in sublinear time relative to the number of points in the embedded space.”
One issue with graphs, however, is the memory cost of maintaining the graph structures, which can be prohibitive for billion-scale problems.
Fortunately, there is a lot of research in the area of similarity search, and some of the most promising activity centers around how to efficiently store and search large databases of high-dimensional vectors that scale to billions of vectors.
In addition to Wayfair, two other companies that are doing a lot of research in similarity search are Microsoft and Facebook. Figure 2 below shows one of the ways that Microsoft handles the issue of searching large databases. They group similar vectors into clusters and search only the portions of the database from the clusters closest to the query image. This significantly narrows down the search candidates that they compare against.
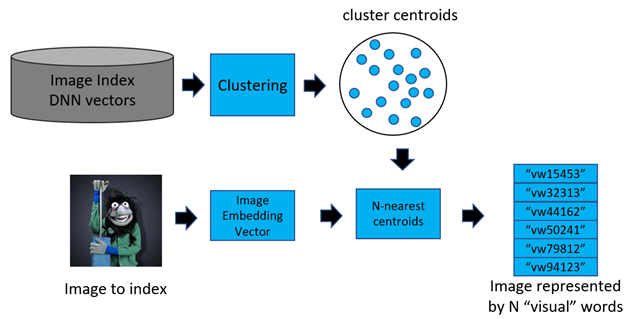
Figure 2: Narrowing the number of search candidates.
Clustering is also used to compress the vectors using a technique known as product quantization (PQ). Companies such as Microsoft and Facebook use PQ to compactly represent high-dimensional vectors. For large datasets, this compression can help to significantly reduce storage requirements. Additionally, it helps simplify the distance calculations used in nearest neighbor similarity search.
Facebook has published research showing how PQ can be used to help address the billion-scale problem. Recently, Facebook has improved their state-of-the-art results in billion-scale problems by incorporating ideas from graph traversal, while also getting around the problem of maintaining prohibitively large graph structures that plague existing graph implementations.




















