- ABOUT GSI
- AI
- HPC
- INDUSTRIES
- AEROSPACE & DEFENSE
- MEMORY
- RESOURCES
- INDEPTH
-
-
AI’s Energy Dilemma

-
-
- INTEGRATORS
-
- TOOLS
-
- INDEPTH


Home Similarity Search: Finding a Needle in a Haystack
Author: Pat Lasserre
In Part 1 of this series, we presented a few examples of how companies are using word2vec-like models to learn semantic embeddings. In this second part of the series, we will discuss how you can use those semantic embeddings as part of a similarity search pipeline in order to provide personalized recommendations at scale.
Personalized recommendations help build customer loyalty, thus making semantic embeddings and similarity search important to many large e-commerce and social media companies.
Similarity search provides a way to find similar items in a dataset. In Part 1, we briefly presented how a few companies learn semantic embeddings for items and place them in a vector space where items that are close to each other in that space are semantically similar. Similarity search uses those embeddings to find the most similar items to a particular query by searching for the closest embeddings to that query. A general term for finding the most similar items is k-nearest neighbor (k-NN), where “k” represents the number of closest items you are searching for.
In general, a similarity search pipeline consists of three main stages: query generation, candidate generation, and ranking.
In Part 1, we covered the query generation stage as the learned embeddings are used to represent the query. In this post, we will cover the candidate generation stage.

Providing relevant recommendations to customers and users is important for e-commerce and social media companies. One of the main challenges for those companies is finding a way to surface the most relevant recommendations (candidates) during the candidate generation stage and to do so in a way that scales with their vast amount of data. Andrew Zhai of Pinterest described the problem best when he compared it to finding a needle in a haystack.
In his presentation, Zhai stated that Pinterest’s candidate generation stage needs to funnel down from billions of images in their visual search pipeline to the most relevant 10,000, or so, images when providing recommendations to their users.
In a blog post, Facebook described a similar challenge to Pinterest’s. Figure 1 below shows how Facebook also needs to funnel down from billions of candidates to a much smaller number of relevant candidates. In Facebook’s example, they are looking to provide the most relevant recommendations to Instagram users.
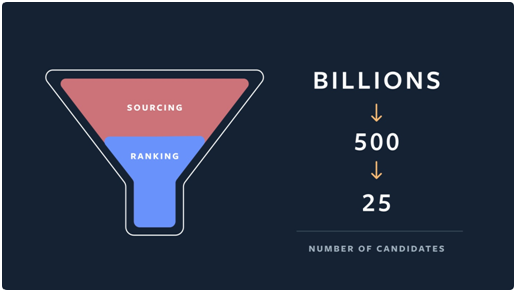
Figure 1 Candidate Generation (Source: Facebook)
In order to find the most relevant content to recommend, Facebook uses the previously mentioned k-NN algorithm.
To do a k-NN search, Facebook uses the account embeddings that were discussed in Part 1, with the account embeddings serving as query vectors. They do a k-NN search to find the “k” most similar accounts to a set of accounts that a particular user previously interacted with. This represents the second stage in the similarity search pipeline — the candidate generation stage.
They then perform the third stage of the pipeline — a finer ranking step on those “k” most similar accounts to create a final candidate list. Facebook canvasses content from that final list of candidate accounts in order to find the most relevant content to recommend to a particular Instagram user.
The conventional way of finding nearest neighbors is to do an exhaustive search of the database, where every point in the dataset is compared to every other point.
With large, high-dimensional datasets such as the billion-scale datasets from Pinterest and Facebook, exhaustive search becomes impractical. Fortunately, there is a way to scale nearest neighbor search which narrows down the search to a smaller portion of the dataset where the k-nearest neighbors are most likely to be found. This technique is called approximate nearest neighbor search (ANN), and we will discuss it in the next, and final, blog post in this three-part series.




















