- ABOUT GSI
- AI
- HPC
- INDUSTRIES
- AEROSPACE & DEFENSE
- MEMORY
- RESOURCES
- INDEPTH
-
-
AI’s Energy Dilemma

-
-
- INTEGRATORS
-
- TOOLS
-
- INDEPTH


Home Demystifying Markov Decision Processes
Authors: Hannah Peterson and George Williams

If you’re just starting to dabble in Reinforcement Learning (RL), it’s very easy to get overwhelmed by the multitude of complex equations and technical jargon you come across in trying to piece together what all the ready-made code out there is doing. And this makes sense—after all, it’d be unreasonable to expect the technology that empowers computers to beat pro-gamers at complex games like Go to be simple. But having some understanding of the inner workings of these state-of-the-art algorithms is important if you want to be able to effectively implement them yourself, and that’s what I aim to develop in this series of blogs.
In this first blog, I’ll introduce Markov Decision Processes (MDPs) and define one in the context of a simple game from OpenAI Gym. In the next blog, I’ll walk-through the equations associated with MDPs to reach the central optimization problem that RL algorithms aim to solve. Then, in the last blog, we’ll actually implement a deep RL algorithm to learn to play a game.
Reinforcement learning can be applied to environments in which actions are associated with rewards, as it consists of teaching a model, known as an agent, which actions to take in an environment to maximize the reward it receives over the course of some process through trial and error. An MDP is a mathematical framework for modeling such systems; in other words, RL is a means of solving problems that can be expressed as MDPs.
Specifically, an MDP is a method for planning in what is known as a stochastic environment, meaning one in which instructing an agent to take a particular action does not necessarily lead to that action being carried out (as opposed to a deterministic environment)—with a small probability, it is up to the environment to decide what happens to the agent. Assuming a degree of randomness in this way is useful for modeling real-world scenarios because the sensory information an agent collects about its environment may have noise associated with it, for example, and accounting for it allows us to build more robust systems.
RL is often applied to gaming because games present isolated environments with explicit sets of available actions and rewards based on those actions, whereas real-world scenarios are typically not so clearly parametrized. For this reason, we will continue to discuss reinforcement learning in the context of a game scenario, which is where OpenAI Gym comes in. If you’re unfamiliar with it, OpenAI Gym is a Python library containing various parametrized game environments that the user can easily interact with using code for the purpose of testing out RL algorithms. Let’s take a look at its simple MountainCar game, which we will be programming in a future post. In this game, the agent is represented by a car whose goal is to overcome gravity by moving left and right to reach a flag at the top of a hill:
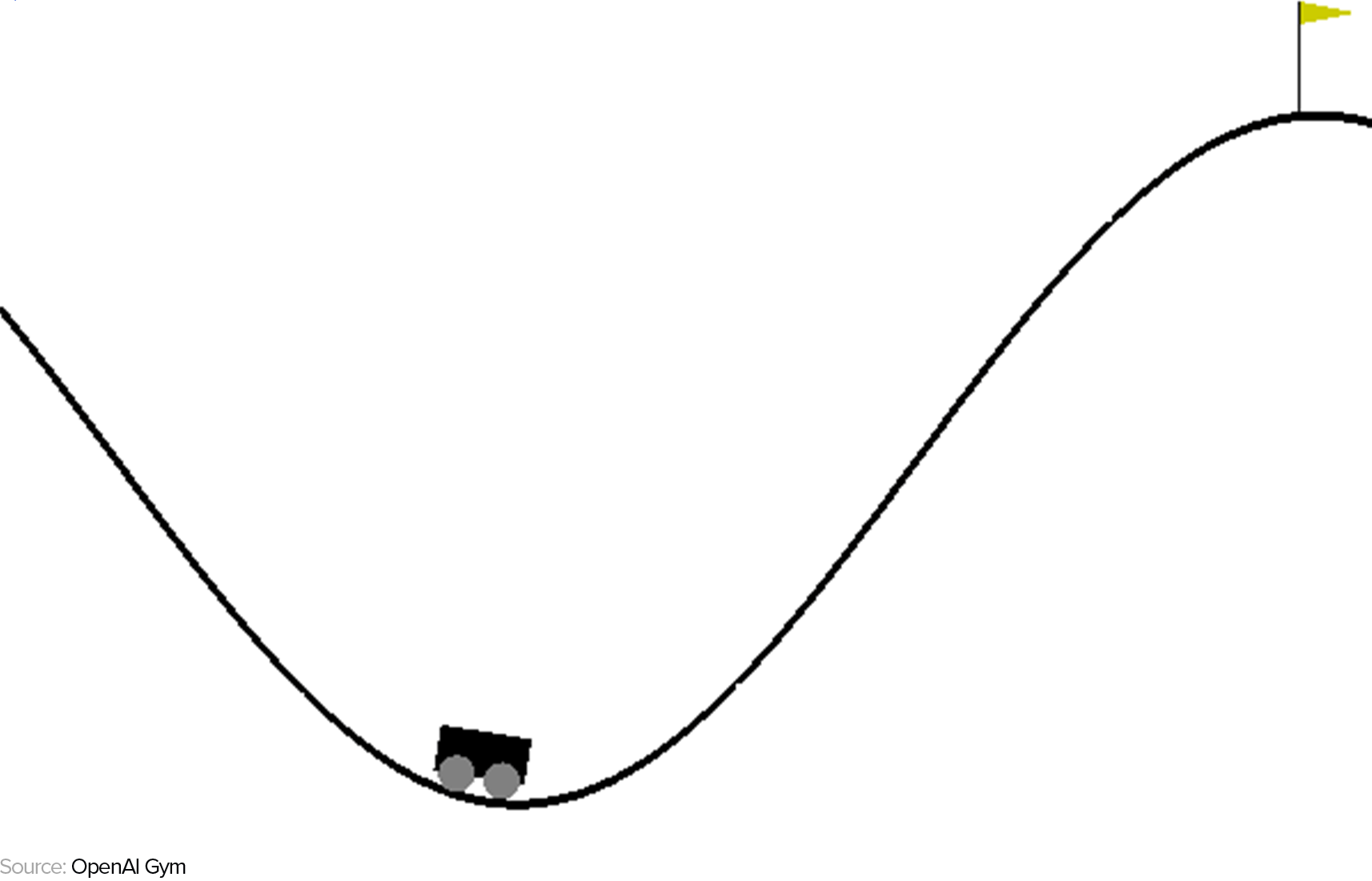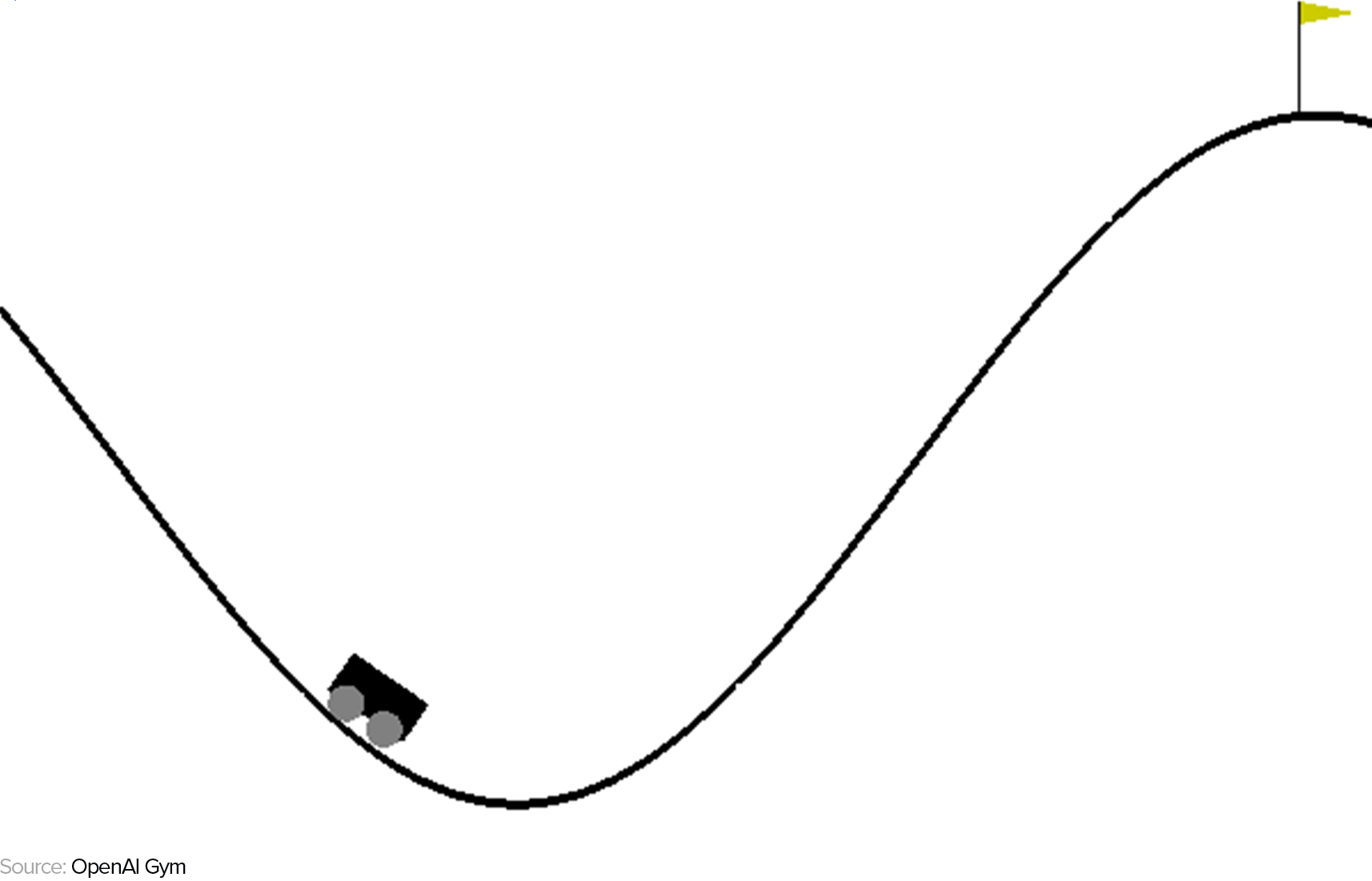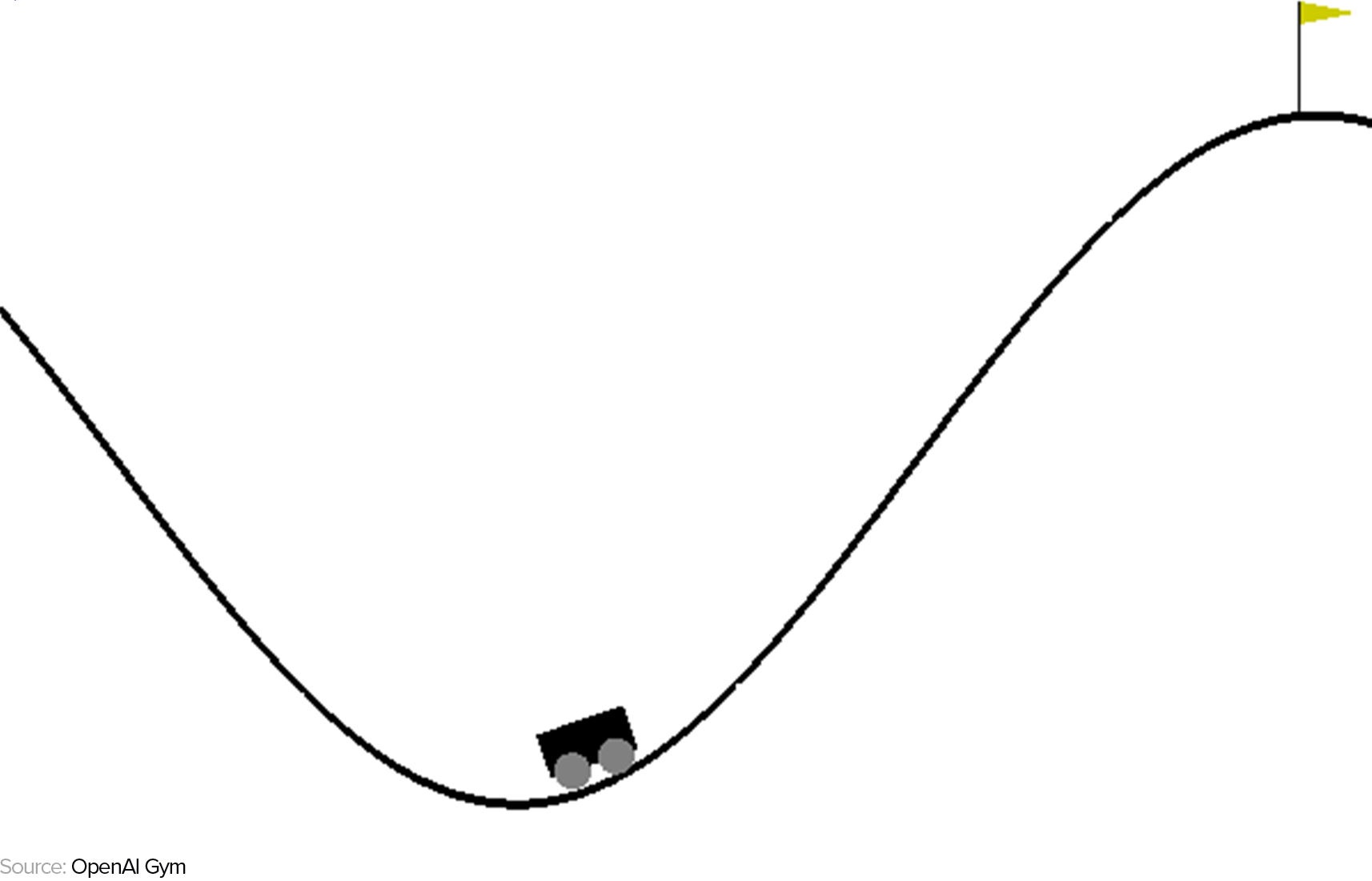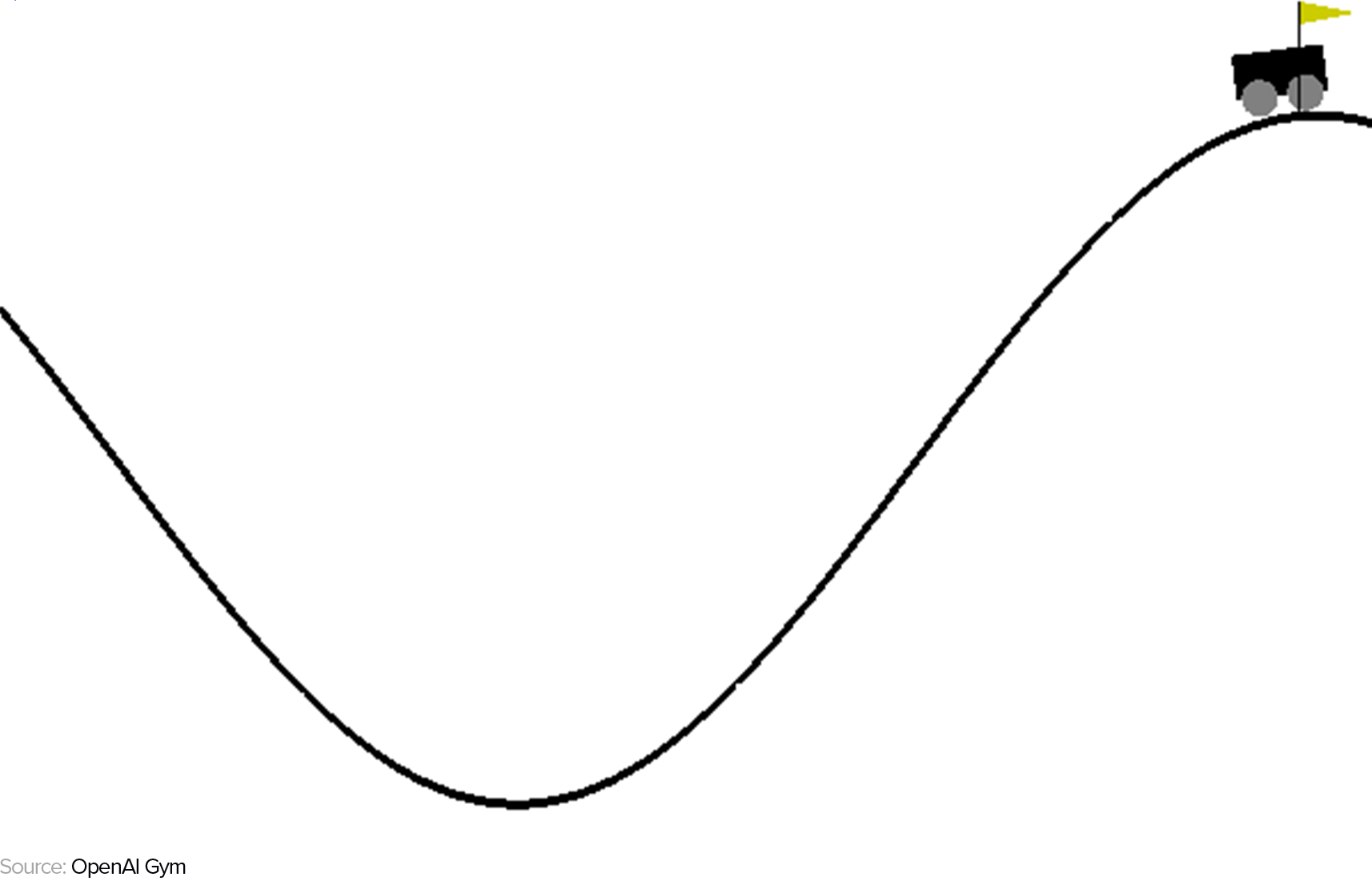
If we want to be able to solve this problem using RL, we need to be able to represent the MountainCar environment as an MDP. An MDP is expressed as a 4-element tuple <S, A, P, R>, where S is the finite set of states the agent can experience in the environment (known as the state space), P is a matrix of probabilities of transitioning between two successive states, A is the set of actions the agent can take to transition between states (known as the action space), and R is the set of rewards the agent can expect to receive in those the states. Let’s break down each element of an MDP in the context of the MountainCar game to better ground them in reality:

We’ve now framed the MountainCar game as a Markov Decision Process. Even within this very simple environment, we can get a sense of the sheer number of possible trajectories available for the agent to take; thus, it needs some means of comparing how rewarding different actions will be—not just immediately upon taking them, but over the course of an entire episode—so that it can choose the paths that will yield the highest rewards. Defining the MountainCar environment as an MDP allows us to use the equations associated with these processes to arrive at a concrete optimization problem for maximizing total reward. We’ll walk through these equations in the next blog.




















