- ABOUT GSI
- AI
- HPC
- INDUSTRIES
- AEROSPACE & DEFENSE
- MEMORY
- RESOURCES
- INDEPTH
-
-
AI’s Energy Dilemma

-
-
- INTEGRATORS
-
- TOOLS
-
- INDEPTH


Home Deep Learning for Radio Waves
Author: Luke Krebs

Satellite
In my last blog I briefly introduced traditional radio signal classification methods; a meticulous process that required expertly handcrafted feature extractors. It turns out that state of the art deep learning methods can be applied to the same problem of signal classification and shows excellent results while completely avoiding the need for difficult handcrafted feature selection.
In this blog I will give a brief overview of the research paper Over the Air Deep Learning Based Signal Classification.
In the past few years deep learning models have out-paced traditional methods in computer vision that, like the current state of signal classification, involved meticulously creating hand-crafted feature extractors. Deep learning provides a hands-off approach that allows us to automatically learn important features directly off of the raw data.
The deep learning method relies on stochastic gradient descent to optimize large parametric neural network models. At its most simple level, the network learns a function that takes a radio signal as input and spits out a list of classification probabilities as output. The model ends up choosing the signal that has been assigned the largest probability. There is no expert feature extraction or pre-processing performed on the raw data. Instead, the network learns important features on the raw time series data.
In this paper, the authors describe an experiment comparing the performance of a deep learning model with the performance of a baseline signal classification method — another machine learning technique called boosted gradient tree classification. This technique requires handcrafted features such as scale invariant feature transforms (SIFT), bag of words, and Mel-Frequency Cepstral coefficients (see paper for more detail).
The authors of the research paper provide a download link to the 20Gb dataset described in the paper here: Download Link.
The dataset contains several variants of common RF signal types used in satellite communication. The self-generated data includes both real signals (over the air) and synthetic signal data with added noise to model real conditions.
Here are some random signal examples that I pulled from the dataset:
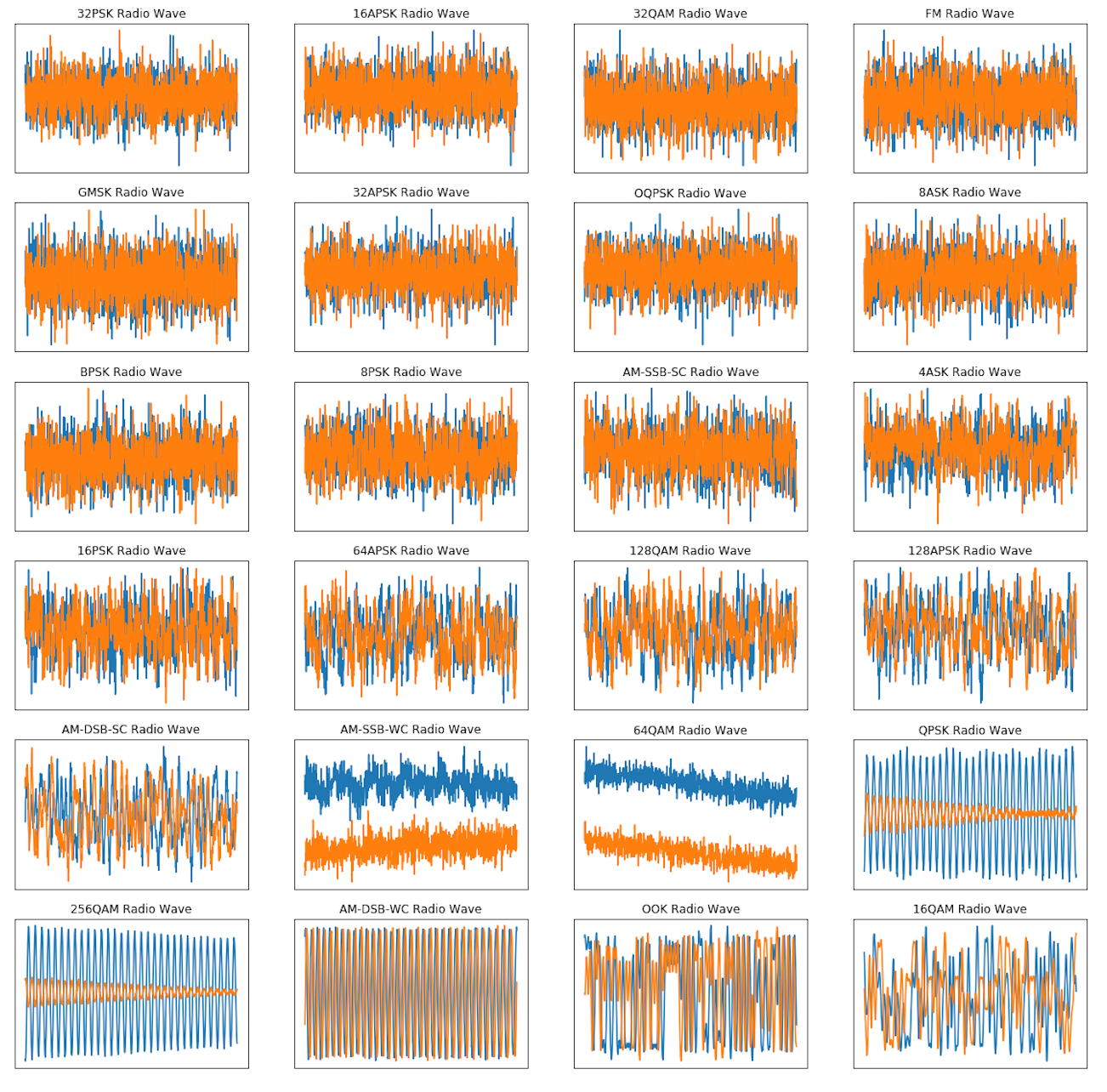
Dataset: 2 million signal examples with varying SNR
Any unwanted signal that is combined with our desired signal is considered to be noise. If you are trying to listen to your friend in a conversation but are having trouble hearing them because of a lawn mower running outside, that is noise.
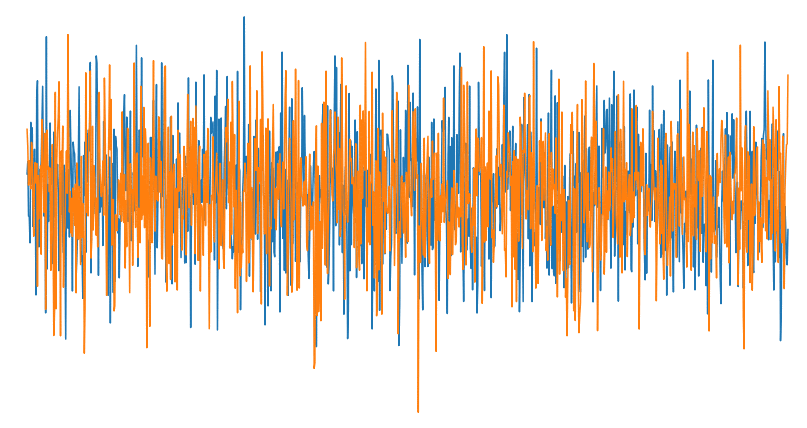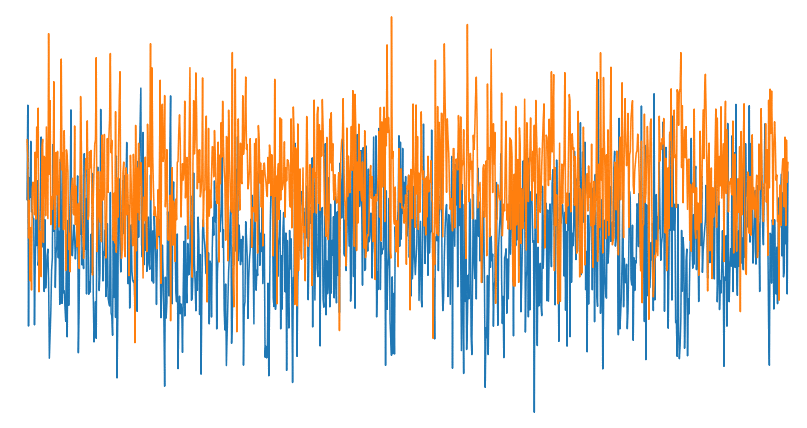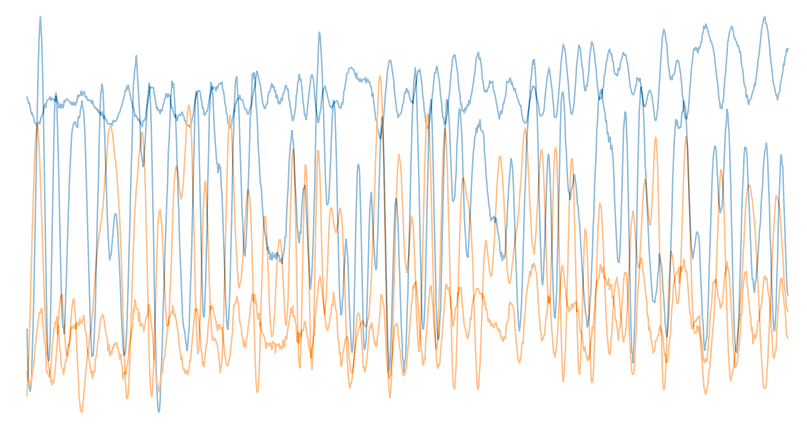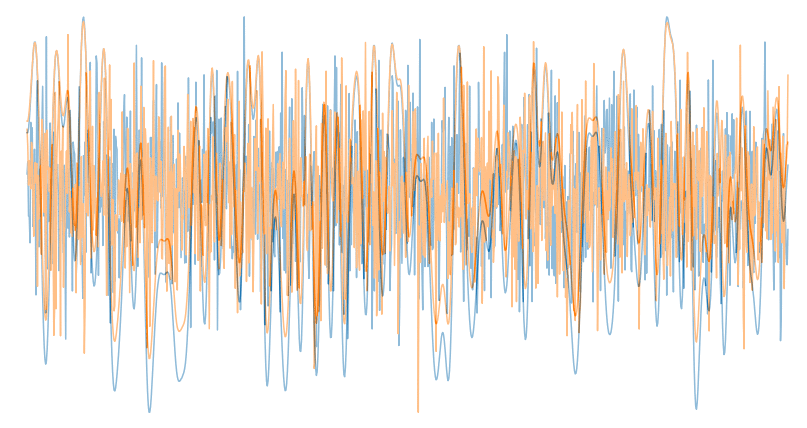
Varying Signal to Noise Ration (SNR)
In the above image you can see how drastically noise can affect our ability to recognize a signal. Signal to noise ratio (or SNR) is the ratio of the signal strength containing desired information to that of the interference. A clean signal will have a high SNR and a noisy signal will have a low SNR. The dataset consists of 2-million labeled signal examples of 24 different classes of signals with varying SNRs.
Each signal example in the dataset comes in I/Q data format, a way of storing signal information in such a way that preserves both the amplitude and phase of the signal. I/Q data is a translation of amplitude and phase data from a polar coordinate system to a cartesian coordinate system. RF communication systems use advanced forms of modulation to increase the amount of data that can be transmitted in a given amount of frequency spectrum.
Now lets switch gears and talk about the neural network that the paper uses.
Each layer of a neural net is a mathematical function that transforms its input into a set of features. By adding more layers, you increase the ability of a network to learn hierarchical representations which is often required for many problems in machine learning. On the other hand adding more layers to a neural network increases the total number of weights and biases, ultimately increasing the complexity of the model. One issue you quickly run into as you add more layers is called the vanishing gradient problem, but to understand this we first need to understand how neural networks are trained.
Neural networks learn by minimizing some penalty function and iteratively updating a series of weights and biases. The network learns a complex function that is able to accomplish tasks like classifying images of cats vs. dogs or, in our case, differentiating types of radio signals.

Back Propagation of Neural Network (source: 3Blue1Brown)
Training happens over several epochs on the training data. In each epoch the network predicts the labels in a feed forward manner. The error (or sometimes called loss) is transmitted through the network in reverse, layer by layer. This is what is referred to as back propagation. As the error is received by each layer, that layer figures out how to mathematically adjust its weights and biases in order to perform better on future data. As the loss progresses backwards through the network, it can become smaller and smaller, slowing the learning process. This is called the vanishing gradient problem which gets worse as we add more layers to a neural network. How do we avoid this problem?
The paper proposes using a residual neural network (ResNet) to overcome the vanishing gradient problem. It accomplishes this by a simple architectural enhancement called a skip-connection. An example of a skip connection is shown below:
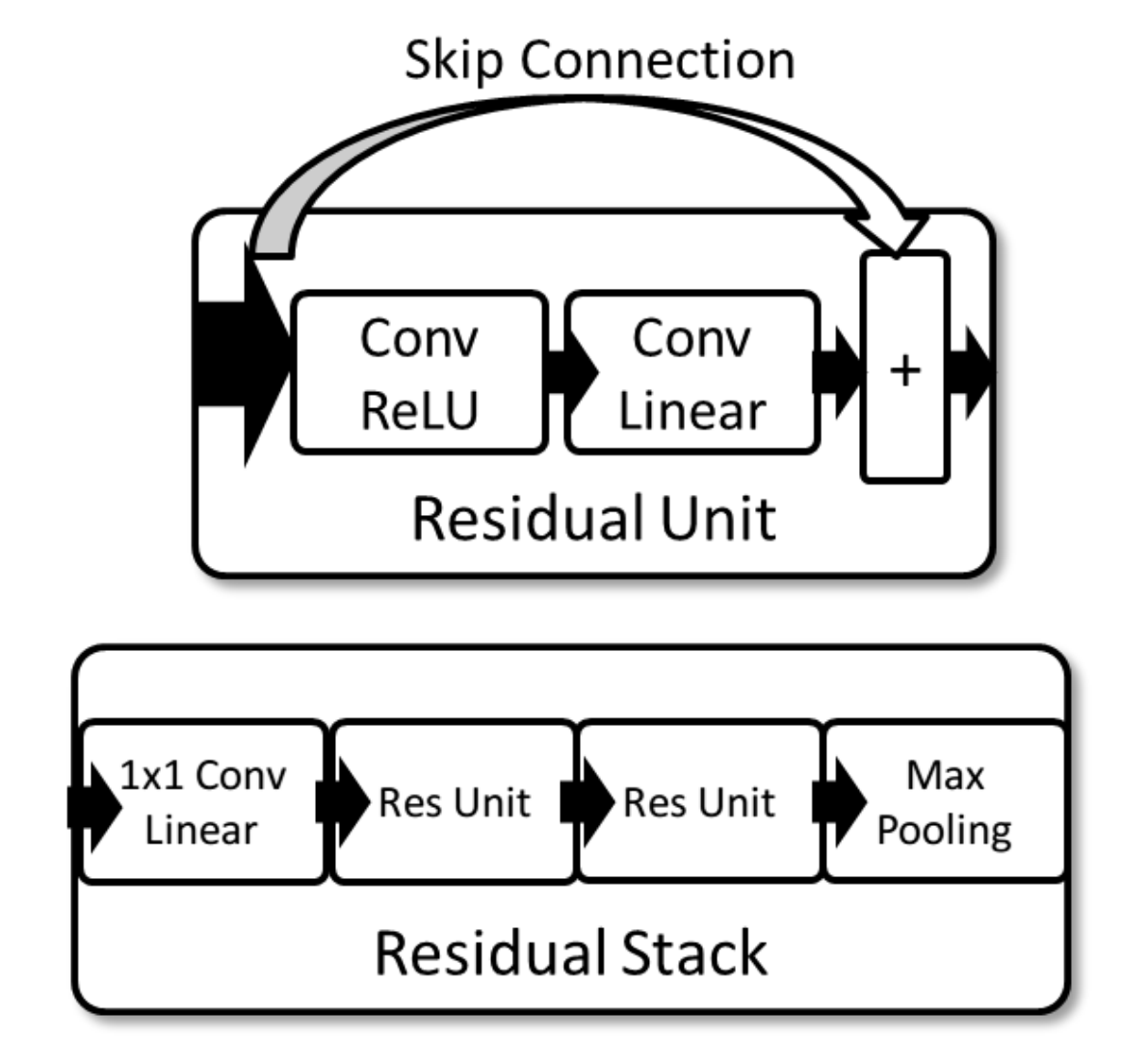
Residual Unit and Residual Stack (source: Over the Air Deep Learning Based Signal Classification)
The skip-connection effectively acts as a conduit for earlier features to operate at multiple scales and depths throughout the neural network, circumventing the vanishing gradient problem and allowing for the training of much deeper networks than previously possible.
Here is the ResNet architecture that I reproduced:
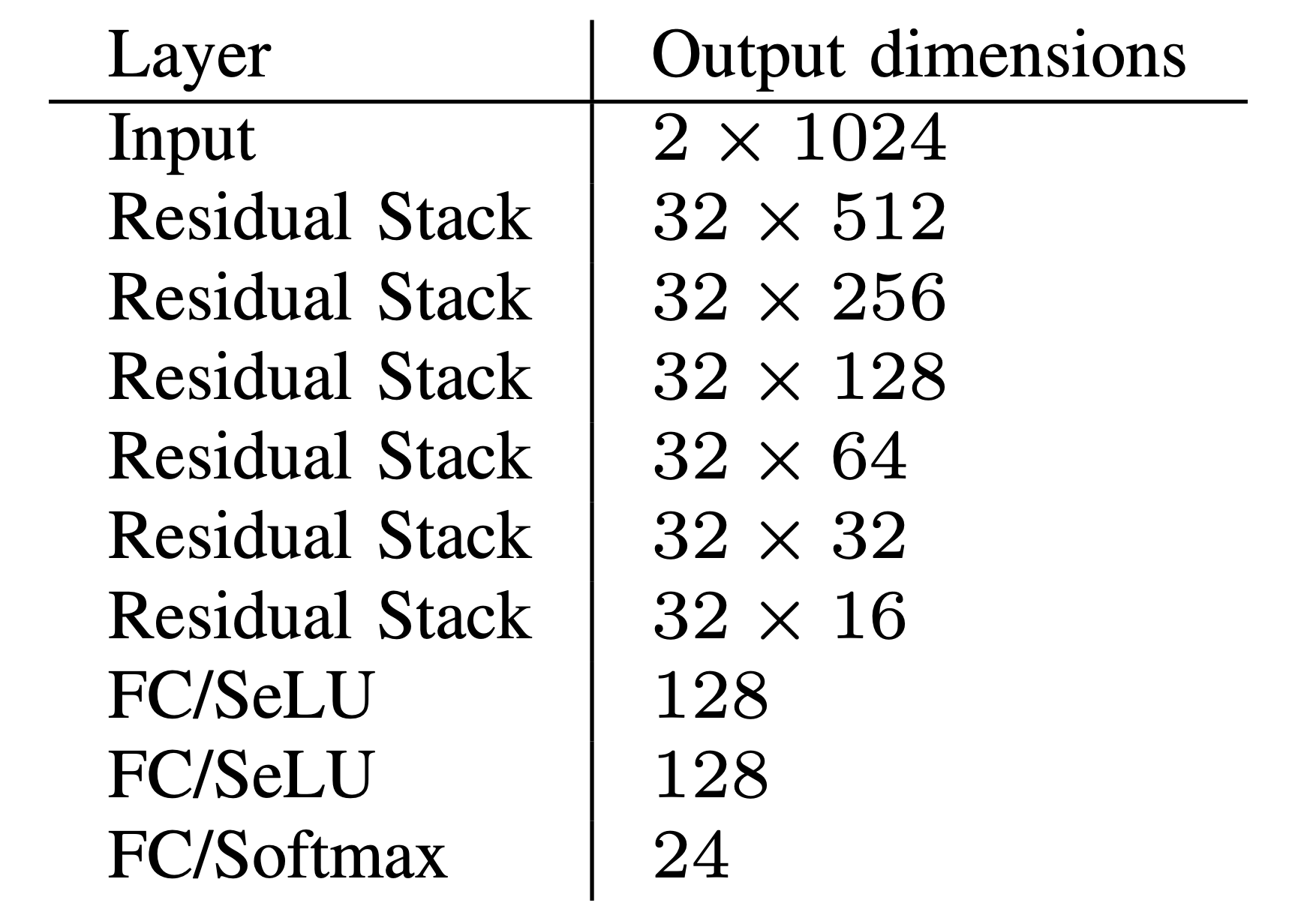
Residual Network Architecture (source: Over the Air Deep Learning Based Signal Classification)
Notice a few things about the architecture:
♦ The architecture contains many convolutional layers (embedded in the residual stack module). Convolutional layers are important for image recognition and, as it turns out, are also useful for signal classification.
♦ The ResNet was developed for 2D images in image recognition. In our architecture, we use 1D layers and convolutions, but the skip connection is generic for any kind of neural network.
Skip connections are very simple to implement in Keras (a Python neural network API) and we will talk about this more in my next blog.
In their experiment, O’shea et al. train a 121 layer deep ResNet with 220,000 trainable parameters on a dataset of two-million signals. They report seeing diminishing returns after about six residual stacks. The data is divided into 80% for training and 20% for testing purposes. The model is trained with an Nvidia Tesla V100 GPU for 16 hours before it finally reaches a stopping point. The authors note that no significant training improvement is seen from increasing the dataset from one-million examples to two-million examples.
For comparison, the authors also ran the same experiment using a VGG convolutional neural network and a boosted gradient tree classifier as a baseline.
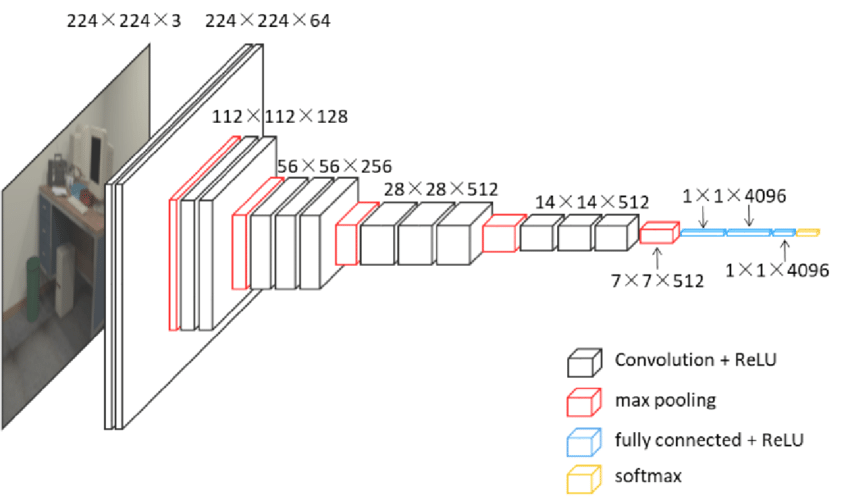
VGG ConvNet Architecture
VGG is a convolutional neural network that has many layers but no skip connections. The boosted gradient tree is a different kind of machine learning technique that does not learn on raw data and requires hand crafted feature extractors.
The ResNet model showed near perfect classification accuracy on the high SNR dataset, ultimately outperforming both the VGG architecture and baseline approach.
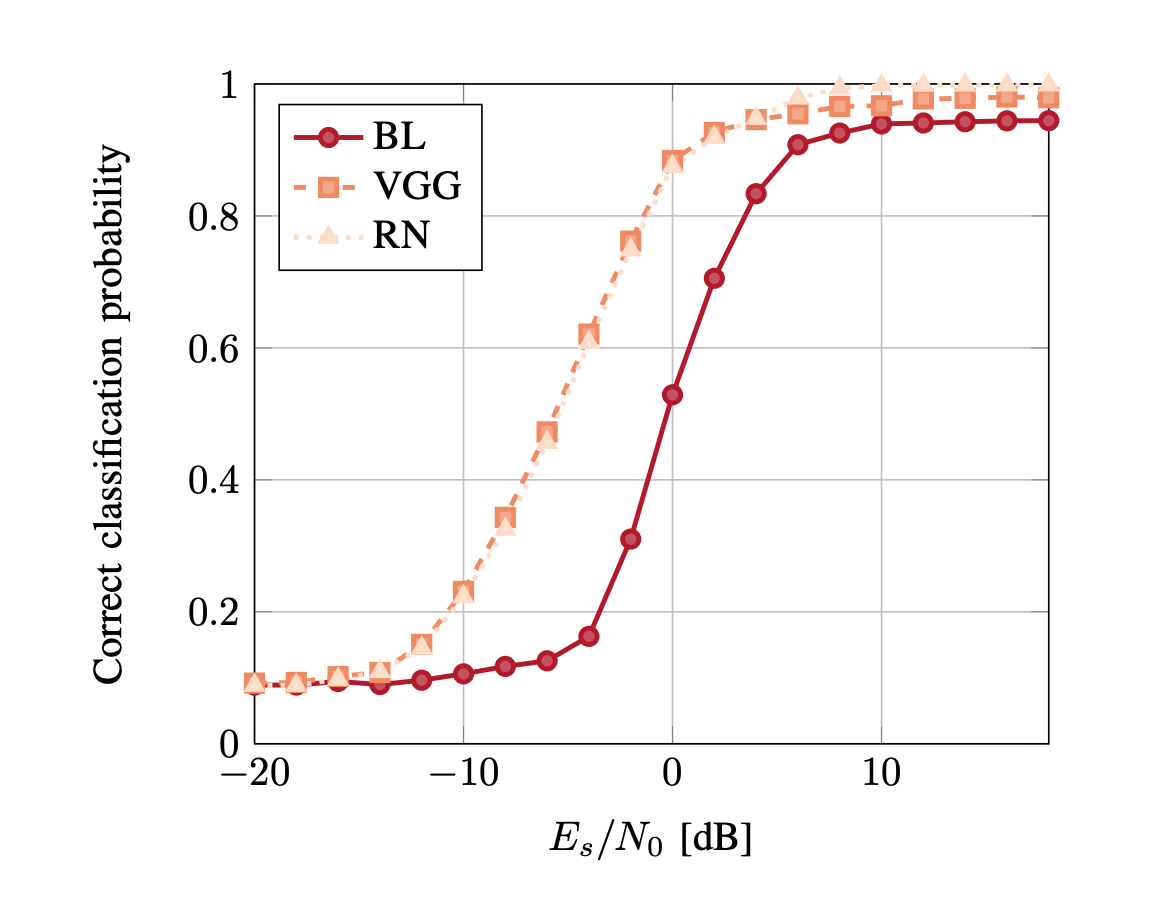
SNR vs. Model Accuracy Graph (source: Over the Air Deep Learning Based Signal Classification)
Notice that the VGG and ResNet deep learning approaches show vast improvements in classification accuracy for lower value SNR signals when compared to the baseline model. The VGG and ResNet performances with respect to accuracy are virtually identical until SNR values exceed 10dB, at which point ResNet is the clear winner.
The ResNet achieves an overall classification accuracy of 99.8% on a dataset of high SNR signals and outperforms the baseline approach by an impressive 5.2% margin.
The model also performs reasonably well across most signal types as shown in the following confusion matrix. A confusion matrix shows how well a model predicts the right label (class) for any query presented to it. — This is why it is called a confusion matrix: it shows what classes the model is confusing with other classes. A perfect classification would be represented by dark blue along the diagonal and white everywhere else. The matrix can also reveal patterns in misidentification.
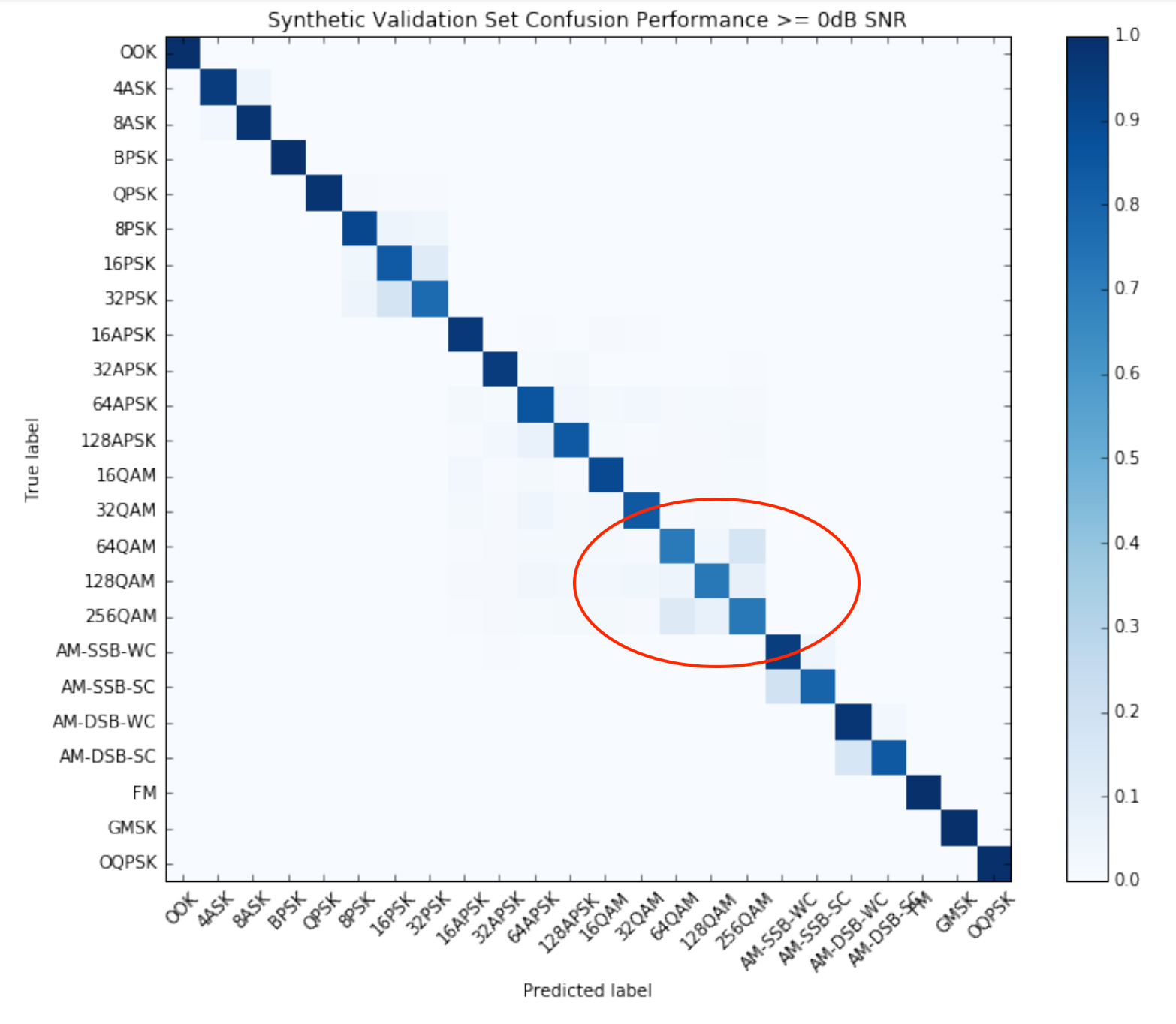
Confusion Matrix (source: Over the Air Deep Learning Based Signal Classification)
For example, if you look at the pixelated areas in the above graph you can see that the model has some difficulty distinguishing 64QAM, 128QAM, and 256QAM signals. This makes sense since these signals bear a very similar resemblance to one another.
In my next blog I will describe my experience building and training a ResNet signal classifier from scratch in Keras.




















