- ABOUT GSI
- AI
- HPC
- INDUSTRIES
- AEROSPACE & DEFENSE
- MEMORY
- RESOURCES
- INDEPTH
-
-
AI’s Energy Dilemma

-
-
- INTEGRATORS
-
- TOOLS
-
- INDEPTH


Home Application of AI to Cybersecurity—Part II
Author: Sabrina Ho
In part 2 of this multi-series blog, I will be reviewing and reproducing the results of the paper — Neural Network-based Graph Embedding for Cross-Platform Binary Code Similarity Detection. As my previous blog mentioned, this paper talks about the application of AI to cybersecurity including malware detection, and vulnerability search. Before we get into that, there are some more basic concepts we need to understand first:
♦ Attributed control flow graph: What is an attributed control flow graph?
♦ Area under the curve (AUC): What is area under the curve? What do we mean by true positive and false positive?
An attributed control flow graph is a control flow graph with vertices labeled as a set of attributes. The image below is taken from the paper we are reviewing in this blog: on the left is a partial control flow graph of code execution, and on the right is the corresponding ACFG.
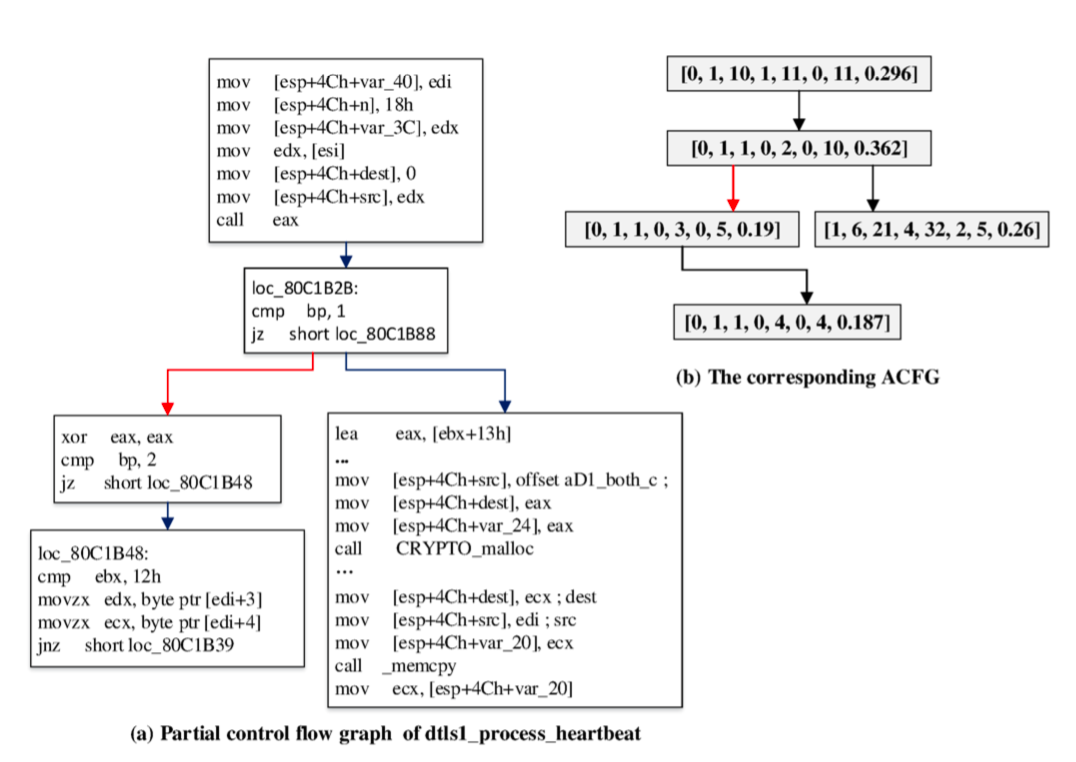
Figure 1 (Reference: from the paper)
Notice that it is taking source code (assembly code) and converting it to a set of attributes and linking those attributes via a graph structure.
The attributes are very important features related to the source code. For more information, see this paper. Control flow graphs are the raw data we use to train a special deep learning model that ultimately can be used to detect code vulnerabilities.
The paper uses AUC as a metric to determine how well the trained model is predicting code vulnerabilities. This metric is related to the notion of true positive and false positive. So, what do we mean by true positive and false positive?
Let’s look at a simple example. Let’s say the doctor determines a patient is sick, but they turned out to be healthy. This is called a false positive. On the other hand, if the doctor says the patient is sick, and they are actually sick — this diagnosis is called a true positive.

The doctor’s performance will depend on a lot of parameters including education, experience, mood, etc. In machine learning, we are also interested in classification and prediction. Just like the doctors, a machine learning algorithm’s performance will also depend on plenty of different parameters.
One common way to measure the performance of a machine learning algorithm is to understand the interdependence of the true positive rate (or accurate prediction) versus the false positive rate (or inaccurate prediction.) This is accomplished via an ROC plot, such as the one below.
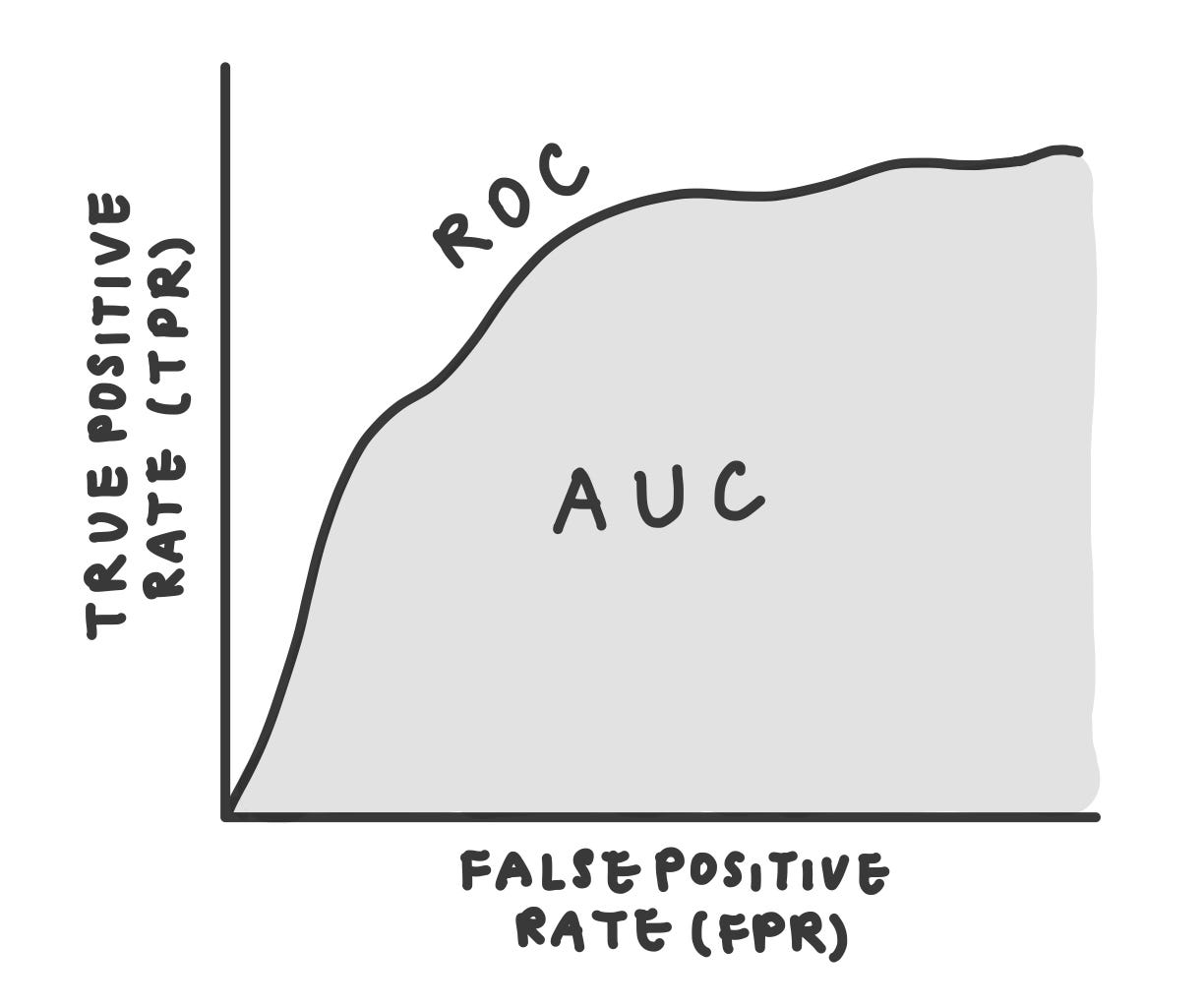
In the plot above, you can see that the ROC curve is the actual line. But many times we just want one number to express the performance of the ROC curve, so then we take the area under the ROC curve. This is called the AUC, which stands for “Area Under the Curve.” This metric is commonly used to compare the performance of different machine learning algorithms, often on the same problem. The higher the score the better — you cannot get better than 1.0, which is perfect classification accuracy. We will be using AUC later to show the performance on how well our models are predicting vulnerabilities.
At a high level, the diagram below shows the model we are trying to train. It is called a Siamese network. This network takes 2 objects (in our case, graphs) and produces an embedding for each graph. The idea is that “similar” graphs will have a small distance between the embeddings while different graphs will have a larger distance. Notice that we use cosine distance as a way to measure similarity of large vectors as opposed to euclidean. Cosine distance is a better metric in high dimensions.
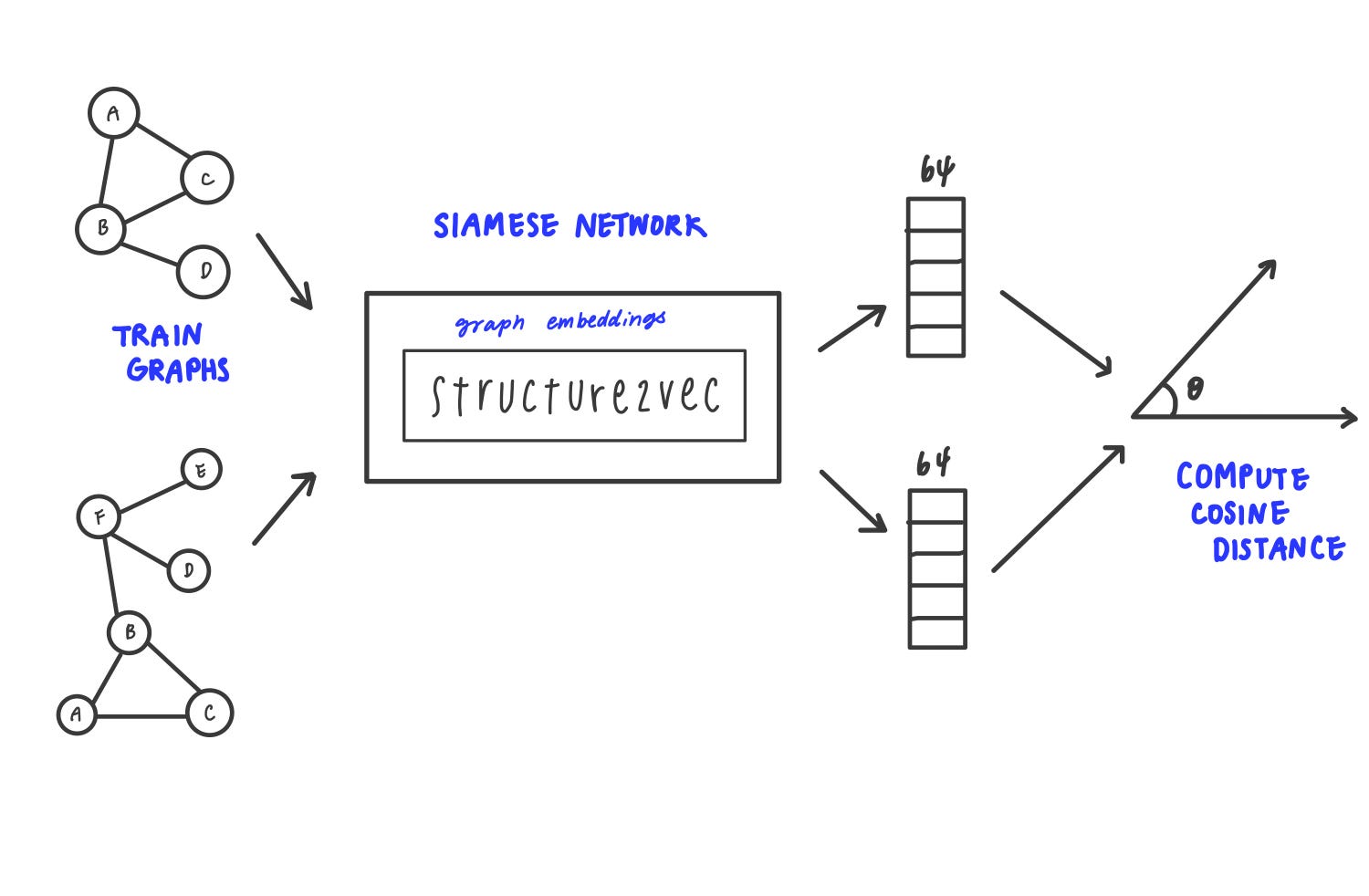
Let’s talk a bit about the training data. As you saw previously, we are using graphs to represent the code. But how do we represent a graph as a matrix or a tensor? Deep learning requires data to be represented in this way.
The authors of the paper showed a clever technique in which a graph is represented by 2 tensors. One tensor is a matrix of all the graph nodes, and the other represents how the nodes are connected (a neighborhood mask.) See the paper or GitHub for more details.
A Siamese network is a neural network that uses the same weight matrix while working with two different input vectors to compute two different output vectors. This network can be applied on all kinds of data. The key is connecting the two output vectors to a loss function.
As mentioned in an earlier paragraph, a cosine distance, which is the similarity score, is computed between two graphs. This similarity score of -1/1 is fed into a Tensorflow function reduce_mean(), which computes the mean of elements across dimensions of a tensor, to generate the loss for training.
loss = tf.reduce_mean( (-cos + label ) ** 2)
We are squaring the value here in order to make it positive. This training produces an embedding for each object in the pair of objects presented to the network.
Now that we know a little bit about the Siamese network, let’s talk about the architecture that hides within it — Structure2vec. As I’ve introduced in one of the previous blogs, it is similar to Word2vec. But instead of a word or document, we are converting graphs into vectors. With this architecture, we can then compute the distance and therefore the similarity between two input graphs. The following shows the specific architecture used in the paper.
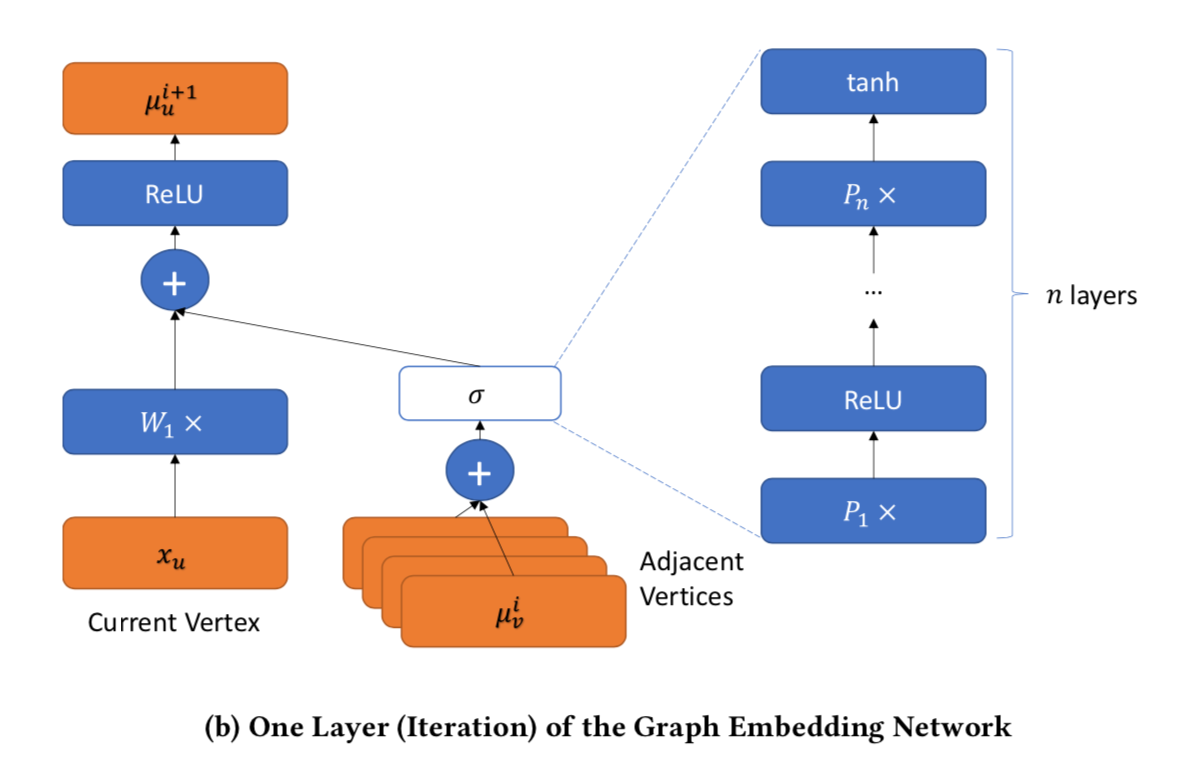
GraphNN is a neural network that produces a 64-dimension embedding vector for a graph. Here are some highlights of how it works (for more details, refer to the paper):
♦ It iterates through all nodes in the graph and uses the neighborhood of nodes’ attributes values to compute the final embedding of the graph by summing them up (refer to Figure 1 in ACFG section.)
♦ It uses ReLU (Rectified Linear Unit) and tanh functions to transform the vectors.
♦ It uses a mask on the graph to find all its neighbors.
I was able to reproduce the results of the paper. I trained over 100 epochs and the final results are as shown below:
AUC on validation set: 0.9749953027021221 AUC on testing set: 0.9717760288125431

Above is a plot for validation, as you can see we got very high accuracy on the validation data. This means I’ve successfully trained the neural network to produce meaningful embeddings for code similarity. In the next blog, I will be using this network and embeddings for code vulnerability search in cybersecurity.
But I want to conclude this blog by discussing a few of the challenges I ran into. I also include some useful tips for anyone who wants to reproduce this code.
1. Reducing training time
When I first started training the models, it took a total of 5 hours and 34 minutes to finish training 100 epoch. This is when I found out about Google Colab. Google Colab started to become popular among the data science world starting beginning of 2019. What’s amazing about is that it provides a powerful GPU to help running the programs, my training model process reduced 2.5 hours compared to running on a strong CPU, which is 1.86 times faster. As incredible as Google Colab sounds, there are still some drawbacks.
♦ Took me a while to get used to the user interface.
♦ Users cannot edit uploaded local Python files in Google Colab. Files have to be edited locally and then upload them again.
♦ It can be challenging to download trained models to your machine.
♦ You don’t get an unlimited amount of memory. Be careful with the resources you’re given.
But here are some useful tips for Colab:
♦ To unzip the data file on Colab, you can use this command directly in the notebook:
!unzip data.zip
♦ Here is how you download saved files (such as trained models) in Colab:
from google.colab import files!zip -r model1.zip saved_model1/
files.download('model1.zip')
2. Mismatches between the paper’s graph and the graph embedding code
♦ In the code, the nonlinear activation function of the node embedding occurs before summing with the neighborhood embeddings.
♦ Also it appears that in the code, the nonlinear code activation embedding is tanh, not ReLU.
3. New vs. Old Versions:
♦ Changing Python2 grammar to Python3
♦ Updating versions of required installations provided in requirement.txt
♦ Correcting Tensorflow grammar to a newer version
4. “InvalidArgumentError: Cannot assign a device for operation….”
This error can be fixed by adding the following two parameters in the graphnnSiamese.py:
config = tf.compat.v1.ConfigProto(allow_soft_placement=True, log_device_placement=True)
By simply doing this, it can automatically assign a GPU to the device without having the device to look for one itself.




















