Home The Role of Transformers in Natural Language Processing Google’s Revolutionary B.E.R.T
Author: Braden Riggs

Pictured: Bert (right) and Ernie (left) from the popular children’s show Sesame Street.
As an undergraduate data scientist, I am often exposed to a range of new topics and ideas shaping the world of data science. Because of the nature of data science, many of these topics span different disciplines or even make up their own disciplines such as the field of natural language processing or NLP. Born out of a combination of linguistics, mathematics, and computer science, NLP is the exploration of drawing data, meaning, and understanding from the swaths of text data in our world. To the untrained eye, NLP may not seem like an important or relatively difficult task. However, its application and importance in our world is undeniable. Technologies such as spam detection, predictive text, virtual assistants, search engines, sentiment analysis, and translators are but a few examples of the plethora of applications for NLP that have become staples in our world. Unfortunately for NLP specialists, human language, be it English or Mandarin, is complicated, messy, and regularly changing, making it very challenging to translate to machines. Because of this difficulty, the field is constantly looking for new techniques and innovations to help machines tackle language and human communication.
Understanding language can be a difficult task, many models have different strategies to achieve this goal. Image credit: NLP & DL (winter 2017) Stanford
One new technique that has helped accelerate NLP is the application of what is called a transformer. Over the course of this article, I will explore some of the key topics you’ll need to understand transformers, the current state of NLP, and Google’s breakthrough transformer BERT.

Much like the language we aim to teach computers to understand, the NLP field is full of jargon, semantic terms, and many layers of complicated topics and ideas. To first understand the role of a transformer in tackling human language, we must understand a little bit about deep learning and neural networks. Neural networks are a form of artificial intelligence that rely on the computer learning from large batches of data. These network paths, much like the neural networks found in the human brain, strengthen and wane as the computer tries to develop probability-weighted associations between the provided input and desired output. Given enough examples, a computer is able to form a structure that can take a previously unseen input and produce a best guess output based off of the relationships it has formed in its training stage.
It is no stretch of the imagination to see how this technology would be effective in helping computers better understand and mimic human language. Just feed the neural net a few classic texts from Shakespeare, Twain, Woolf and Douglas Adams, for good measure, and it will be able to understand human language in no time, right? Unfortunately, this is not the case, and whilst neural nets are a great step in the right direction, they are really only a piece of the puzzle that is human language. This is because the words that make up language aren’t independent from each other; a series of words can take on new meaning with the addition or subtraction of other words which makes the process of understanding text much more complex. Neural networks struggle to understand the relationships of sequential words and phrases even if supplied with ample training data.
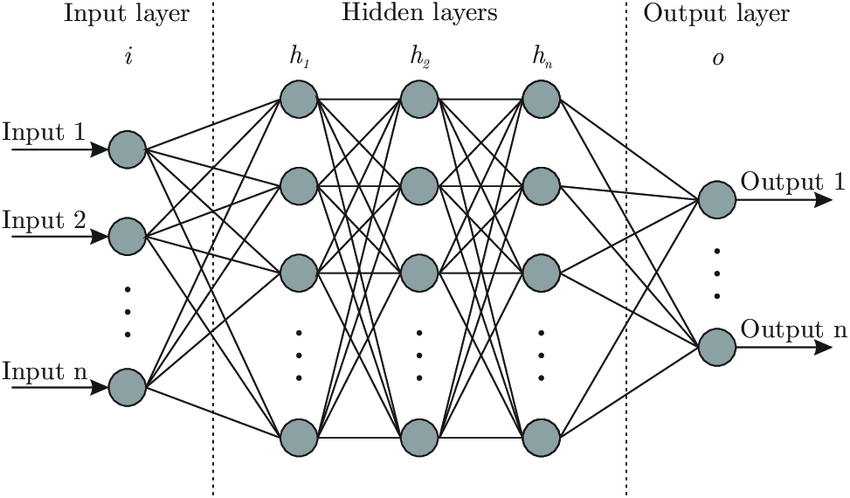
Pictured is a visual representation of a neural network, in our case “input” would be books/text, the “hidden layer” would be where the model learns the relationships between words, and the “output” our desired outcome, such as a translation of the input text.
The response to this neural net pitfall is the creation of the recurrent neural network, or RNN. Language cannot be thought of as a series of isolated words laid out in sequential order, but rather a series of interrelational words that are constantly interacting with each other throughout the sentence, paragraph, and whole text. For this reason, RNN’s are more effective. The “recurrent” in the name RNN is a great clue as to how this technique better overcomes the challenges of language as opposed to a traditional neural net. In essence, a RNN loops through the data, chaining together relationships between data points in a more computationally expensive process. Rather than trying to understand a whole movie from a one-second snippet, a RNN would look at all the snippets in the film and how they connect to better understand what is going on. A RNN can be thought of as a series of neural nets, each chained together based on what has come before it. This can be done with varying intensity but ultimately proves to be more effective and a better system for understanding and working with language.

Pictured is a visual representation of the “recurrent” aspect of an RNN that takes place in the hidden layer stage. Note how the inner nodes are retrained on the adjacent nodes.
RNN’s are often implemented as sequence-to-sequence models; a type of solution to conversion problems such as translation. Since most data is structured in some form of a sequence, such as a sequence of words (a sentence) or a sequence of pixels in an image, a seq-2-seq model can encode the sequence into a vector of fixed length, then decode the vector into the desired output, such as a French translation of an English phrase. Unfortunately, this problem becomes computationally more intensive as the sentences get longer or more sentences are involved. According to Bahdanau et al’s paper “Neural Machine Translation by Jointly Learning to Align and Translate”, this encoder-decoder bottleneck is caused by the use of fixed-length vectors. Essentially, encode-decoder RNN’s compress all the information of a sentence into a fixed-length vector. This causes the model to struggle with sentences that are longer and hold more information than those found in the training set, causing performance and accuracy to dip dramatically. In Bahdanau’s paper, he proposed a solution to this issue, a concept he describes as the ability for the encoder-decoder model to align and translate jointly; a concept that would later be called attention.

Just like when we read attention is an important part of language’s puzzle.
Attention, in essence, can be thought of as a “bang for your buck” method for encoder-decoders. Because the model is under significant limitations, rather than trying to understand the entire input, it instead only pays attention to the parts of the input where the most information is concentrated. It does this by utilizing context vectors which point to the most information-dense parts of the sentence to help the decoder maximize how much meaning it can extract from the input vector. This has the added advantage of allowing the decoder to develop its own schema for the decoding process. Using language translation as an example, we know that French and English are quite similar in structure and sentence composition, but English and Japanese are not. Through utilizing the power of attention, the model is able to arrive at this conclusion independently and focus more on decoding from the important regions of the text. Because of the structure of Japanese, which starts with the subject and ends with the verb, the attentive model is able to shift weighting to account for these differences when translating to English or vice versa. This contrasts heavily with traditional encode-decode models which would attempt to understand Japanese as if it was of similar structure to English. Borrowing a visualization from Denny Britz’s discussion on the topic of attention we can actually see this process in action for a translation from French to English:

Visualization borrowed from Denny Britz’s Attention and Memory in Deep Learning and NLP
In Britz’s visualization, the brighter the square the more attention the model paid to that particular word. As you can see, the model was able to discern the inverting of armes chimiques to chemical weapons.
Whilst attentive models are a significant leap in the field, they still struggle with long dependencies such as relationships between words that can span multiple sentences. Luckily, there is a solution to this problem- transformers.
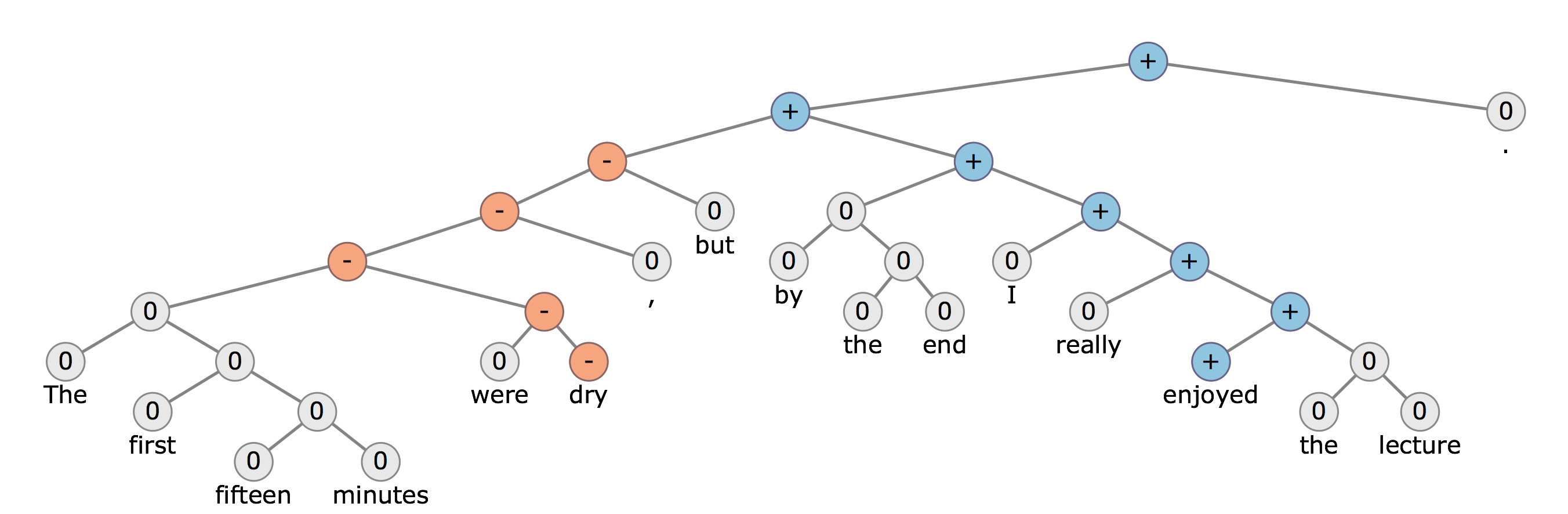
It turns out attention is a really powerful tool in the world of NLP. As the paper “Attention is all you need” points out, attention is really all you need. In a revolutionary breakthrough the team was able to prove that an attentive model, without a RNN, can improve results in a number of NLP related tasks. This new model, a transformer, would instead run parallelized attentive mechanisms amongst other techniques to produce a better schema of the text it was encoding and decoding. This new model proved its efficacy by having a lower training cost and a higher BLEU score; a score used to evaluate the quality of machine-generated translations. A score of 100 is a perfect match to a human referenced translation. These results can be seen here, compared to other state-of-the-art algorithms:
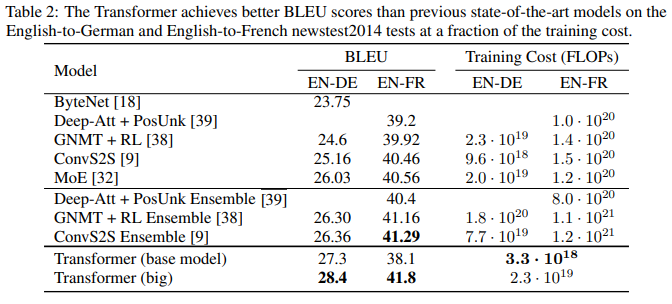
Table taken from “Attention Is All You Need” page 8.
With so many breakthroughs in the last decade, it is hard to imagine that there would be more innovations and improvements to discuss, but there are. Finally, we have come to B.E.R.T — also know as Bidirectional Encoder Representations from Transformers. Developed by Google’s AI Language lab in mid-2019, BERT is one of the latest innovations in the world of transformers and NLP, combining the power of transformer technology with a new bidirectional strategy. Whereas earlier implementations of transformers relied on unidirectional learning, BERT instead reads the text in both a traditional left to right manner and an unconventional right to left manner to better understand and train itself on the text. This gives the model a deeper understanding of the text, as meaning can be drawn out from both directions.
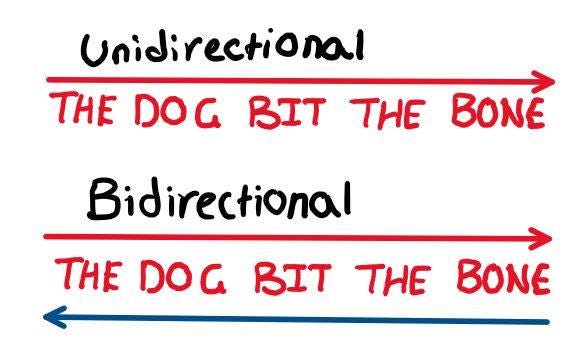
The bidirectional encoder would also read “bone the bit dog The”
BERT also has a few other tricks up its sleeve to help eke out more accuracy. One technique, “masking”, involves altering roughly 15% of the words in a sentence. Of the altered words, 80% are replaced with a “mask” token which functions as an unseen word, 10% with a random word, and 10% with the original word. Then BERT evaluates its own predictive accuracy based on the clues that surround the altered words. As it succeeds in this process, the model considers only the effectiveness of its predictions on masked words and tunes itself accordingly. As seen on the graph below, BERT converges more slowly and to a higher threshold than a BERT implementation without masking:

Appendix C.2 of BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
What I found fascinating when learning about masking was how including random words or keeping the original words impacted the accuracy of the model. Google’s landmark paper on this topic also explored the role random and original words played in the effectiveness of the masking technique:
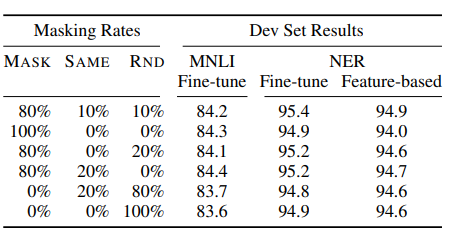
Appendix C.2 of BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
As you can see, the trade-off between the mask token (Mask), same word (Same), and random word (Rnd) can have a variety of impacts on the accuracy of the model. One of the major issues with replacing 100% of the works with the mask token is the impact on the feature-based approach from NER. Named Entry Recognition or NER, is a score that relates to how close the model got to correctly identifying the features of the text, such as names, organizations and places. For example if our text is:
“Jane Doe is a student at the University of Queensland”
Then a model with a high score would have correctly identified Jane Doe as a person, student as an occupation, and University of Queensland as an academic institution. A model with a low score would have failed to identify these elements or incorrectly identified other elements in the text.
As apparent from the above table, there is a drop-in feature-based NER accuracy which results from the model’s inability to produce effective token representations when 100% of the altered words are masked. Hence, the most effective masking rate was an 80–10–10 split.
In addition to masking, BERT also trains with a technique known as “next sentence prediction”, where one half of the time the model is given subsequent sentences, and the other half of the time the model is given two random sentences. It then predicts if the second sentence is subsequent to the first sentence based on the word tokens within both strings of text. The sentence is marked with a [CLS] token to signify the start of the sequence, and a [SEP] token to signify the end of each sentence:
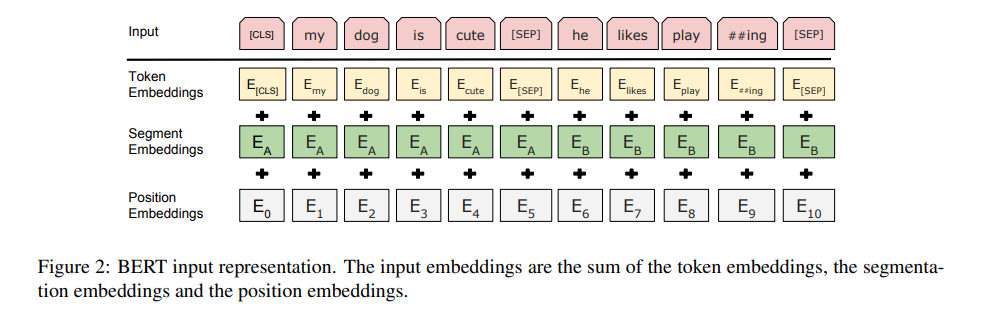
A visual example of next sentence prediction
As in the example above, BERT would discern that the two sentences are sequential and hence gain a better insight into the role of positional words based on the relationship to words that can be found in the preceding sentence and following sentence.
These methods in conjunction help elevate BERT to a high level of performance when compared to traditional transformers, and especially when compared to RNN’s. BERT also sees increased accuracy across a number of different metrics when trained on larger and larger datasets:
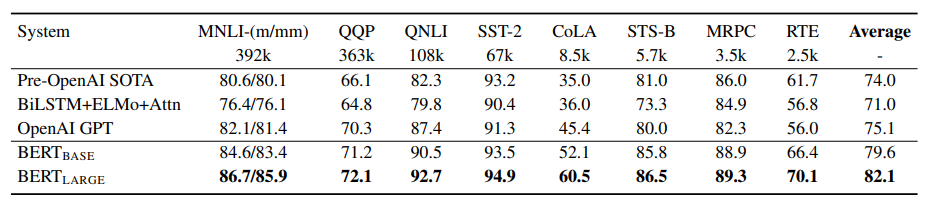
Results of popular NLP models compared to BERT_base and BERT_large
Explanations and examples of the scoring metrics seen in the above table can be found in the appendix.
As you can see from the table above, BERT_base trained on 110 Million parameters scored notably lower than BERT_large, which was trained on 345 Million parameters. This suggests that the effectiveness of the model could edge higher given even larger training sets.

Exploring the impact of different masking implementations on BERT will be a great next step
As clearly evident, the world of NLP can change at a moment’s notice as new and improved ideas shake the status quo. One topic I am particularly interested in exploring further is the impact of masking on the accuracy of the final model. In part two of this series on BERT I plan to dive deeper into what makes the model tick and why masking works so well. Readers can expect to see a little more hands-on data science as I attempt to recreate the masking results in appendix C.2 of the paper “Pre-training of Deep Bidirectional Transformers for Language Understanding” and explore why certain masking implementations outperform others.
Some of the noteworthy metrics in the B.E.R.T. table above include:
“I have an itchy rash on my heel?” vs “On my foot, there is a red itchy spot near the heel?”. Given the similarity, these two questions are likely referring to the same condition and hence should be paired.
“That movie was THE worst” vs “The movie is one of my new favorites”. Given these two sentences, a score of 100% would be correctly identifying the first review and negative, and the second review as positive.
“If you help the needy, God will reward you” and “Giving money to a poor man has good consequences”. Given the first sentence is it logical to deduce the second sentence.
More information on the scoring metrics can be found here. And the global leaderboard of NLP models can be found here.
Bahdanau, Dzmitry, Kyunghyun Cho, and Yoshua Bengio. “Neural machine translation by jointly learning to align and translate.” arXiv preprint arXiv:1409.0473 (2014).
Britz, Denny. “Attention and Memory in Deep Learning and NLP.” WildML, 27 Apr. 2016, www.wildml.com/2016/01/attention-and-memory-in-deep-learning-and-nlp/.
Devlin, Jacob, et al. “Bert: Pre-training of deep bidirectional transformers for language understanding.” arXiv preprint arXiv:1810.04805 (2018).
Jain, Sarthak, and Byron C. Wallace. “Attention is not explanation.” arXiv preprint arXiv:1902.10186 (2019).
Levine, Ben. “Character-Based Neural Networks for NLP in the Real World.” Oracle Data Science, blogs.oracle.com/datascience/character-based-neural-networks-for-nlp-in-the-real-world.
Nigam, Vibhor. Natural Language Processing: From Basics, to Using RNN and LSTM. 12 June 2020, towardsdatascience.com/natural-language-processing-from-basics-to-using-rnn-and-lstm-ef6779e4ae66.
Serban, Iulian Vlad, et al. “A hierarchical latent variable encoder-decoder model for generating dialogues.” Thirty-First AAAI Conference on Artificial Intelligence. 2017.
Vaswani, Ashish, et al. “Attention is all you need.” Advances in neural information processing systems. 2017.





















