Home Application of AI to Cybersecurity—Part III
Author: Sabrina Ho
This is the final blog in my 3 part series, where I explore the application of AI in cybersecurity. In part 1, I introduced some concepts that are important for this topic, including: control flow graphs (CFG), firmware, and graph embeddings. In part 2, I talked about attributed control flow graphs (ACFG) and discussed the concept of area under the curve (AUC.) In this final blog, we bring all these concepts together and discuss how code similarity search can be applied to the problem of vulnerability and malware detection.
Why do we care about vulnerability and malware detection? This is a very important aspect of cybersecurity. When hackers break into a computer, they can take advantage of bugs or badly written software (often called vulnerabilities) and inject their malicious code (for example, malware.)
This is a very big problem right now. For example, here are a few recent high profiles of cybersecurity attacks:
♦ “22 Texas Towns Hit With Ransomware Attack In ‘New Front’ Of Cyberassault”
♦ “Cybersecurity: New hacking group targets IT companies in first stage of supply chain attacks”
♦ “Cybersecurity: 99% of email attacks rely on victims clicking links”
This is not a solved problem and getting worse. Look at the charts below, which show that cybersecurity attacks are getting more costly and companies are paying more for cybersecurity products to protect themselves.
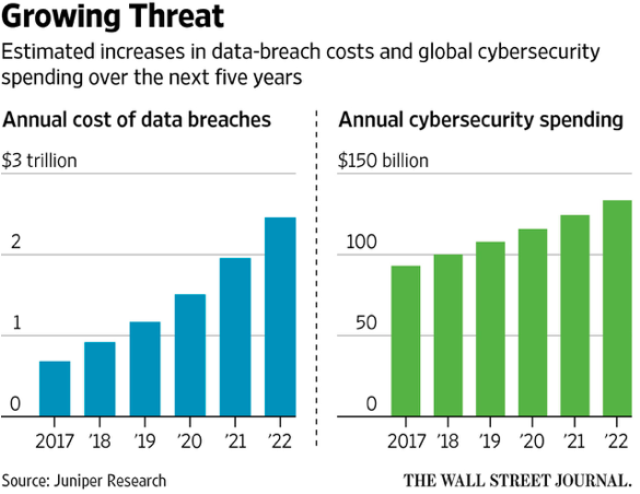
Source: InfotechLead
How can similarity search be an effective tool to solve these problems? The idea is simple. Take a piece of software, such as a function in software, and then search a database of known vulnerabilities or malware. Then you can classify the query based on the most similar matches in the database.
For example, look at the image below taken from this paper. This is a visual representation of a small portion of a database that contains all the functions of the openSSL library, an important encryption library used by many systems. Each dot represents a function in the library. Dots that have the same color are different variations of the same function (compiled for different hardware architectures and operating systems.)

t-SNE depicting code similarity of openSSL encryption functions
Some of the functions in the database contain vulnerabilities and were exploited by hackers in the past (see Heartbleed cyberattack.) The full database is not shown and has 129365 data points.
Why is this useful? Let’s say you have a piece of software, like firmware for an IoT device and you want to determine whether the functions in there are similar to known openSSL vulnerabilities. You would take all the functions in the firmware and perform a similarity search against the database. If a query is close to any clusters and that cluster represents a vulnerable openSSL function, you can likely classify the function as also being vulnerable.
But how do we make this fast and accurate? That was the topic of the paper — Neural Network-based Graph Embedding for Cross-Platform Binary Code Similarity Detection, which was the inspiration for this blog series.
The key to making code similarity search fast is to convert the software into a much smaller representation. The paper takes the following approach:
♦ First, the software is broken up into functions.
♦ Each function is converted into an attributed control flow graph (for background, see part 2.)
♦ The control flow graph is converted into a 64-dimensional vector (often called an embedding.)
♦ Then search is performed against an embedding database of known vulnerabilities and malware.
How is a graph converted into a vector? This is accomplished through a neural network. The paper used a model called Structure2Vec, which is one way to convert an arbitrary graph structure into a compact vector. The image below shows the architecture:
Structure2Vec Neural Network, which produces an embedding given an arbitrary graph
The key is that the neighborhood around each vertex of the graph contributes its attributes to the overall graph embedding (for more details, see part 2.)
Now, how does this model enforce similarity and dissimilarity of the embeddings? This is accomplished during training using the Siamese architecture shown below:
Siamese Network, which forces embedding pairs to be close or far depending on code similarity
Notice the cosine distance computes a similarity of two embeddings in the high dimensional space. During training, we forced the embeddings to be close to each other by 1) choosing pairs in the training data are similar and 2) setting the cosine distance to 1. Also, we forced embeddings to be far apart by 1) choosing pairs in the training data that are dissimilar and 2) setting the cosine distance to -1.
The end result is a model that produces compact of representation of software that is useful for fast and accurate code similarity search.
As we showed in the last blog, we can train the model to produce a highly accurate embeddings for code similarity and we can achieve an AUC score of 97%.
As we can see code similarity search can be an effective tool in determining whether or not a piece of software contains a vulnerability. Although we do not show it here, the same similarity search technique can be used to classify arbitrary code as malicious or malware.
In future work, we plan to investigate a few other directions inspired by the work we did for this blog series:
♦ Test against much larger databases of known vulnerabilities and malware.
♦ Explore other graph embedding techniques such as DeepWalk.
♦ Investigate other contrastive loss architectures including triplet loss.
♦ Learn even more compact numeric representations called binary codes, a bit vector instead of a floating point vector.
♦ Explore other techniques to visualize this type of vector database since we found t-SNE very challenging for this kind of dataset.
♦ Plan to use GSI Gemini similarity search accelerator technology to speed up similarity search since performing code similarity search on a large database (millions of data points) will likely be slow without some help.





















