- ABOUT GSI
- AI
- HPC
- INDUSTRIES
- AEROSPACE & DEFENSE
- MEMORY
- RESOURCES
- INDEPTH
-
-
AI’s Energy Dilemma

-
-
- INTEGRATORS
-
- TOOLS
-
- INDEPTH


Home Integrating Textual and Visual Information Into a Powerful Visual Search Engine
Author: Pat Lasserre
GSI Technology recently hosted a panel discussion on visual search at ODSC West 2018. The panel featured presentations from Clarifai, eBay, Google, Walmart Labs/Jet.com, and Wayfair.
This blog post summarizes Walmart Labs/Jet.com’s panel presentation from the conference. Their presentation showed how they used Elasticsearch, a popular text search engine, to build a visual search engine that works with their existing text search engine.
The rest of this blog post was contributed by Guang Yang, Cun (Matthew) Mu, Jun (Raymond) Zhao, Jing Zhang, and Zheng (John) Yan from Walmart Labs/Jet.com, and it describes their architecture.
We recently presented our learnings from building an end-to-end visual search engine using TensorFlow Serving and Elasticsearch at ODSC West 2018 and in a SIGIR 2018 paper. Our goal is a content-based image retrieval system that works seamlessly with our existing text retrieval system to support search and recommendation. We started this journey in Apr. 2017, when we built the first prototype at Jet.com Innovation Time (JIT) — a 3-day hackathon. We continued our research while our learnings were incorporated into the production system.
Our visual search system consists of 3 microservices:
– a representation learning model that maps images into numeric vectors where more similar images are mapped closer to each other in a vector space
– an encoding strategy that encodes each vector into a collection of string tokens where vectors that are closer to each other share more string tokens in common
– a search engine that supports continuous deployment in production, and coherently integrates both textual and visual information
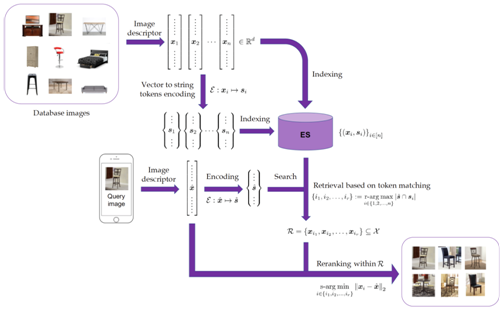
Figure 1: Visual Search Engine Architecture Overview
The representation learning model enables us to find images that are similar to a query image by searching for images whose vectors are close to the query’s vector. It might be preferred to retrain the deep learning model based on your own image catalog data. However, we found that an open-source pre-trained model such as Google’s Inception-ResNet-V2 can still work well in cases where one does not have the resources to label images and retrain the model.
At first glance, an encoding strategy that maps the numeric vector to string tokens seems redundant, but in the following sections we will show why it is beneficial.
Initially, we did not include the numeric vector to string tokens mapping. Searching k-nearest vectors was accomplished by calculating L2 distance using Facebook AI Similarity Search (FAISS) . However, we found several difficulties when we tried to integrate it with our existing text search system in production. We used Elasticsearch, but the difficulties we encountered are not unique to Elasticsearch — they also apply to other text search systems, such as Solr or Sphinx.
The first difficultly that we faced is that FAISS hosts its index in Random Access Memory (RAM), which is much more expensive than disk storage space. Although FAISS provided several methods, such as product quantization (PQ), to compress the numeric vector and save memory space, such compression reduced the search quality. As shown in Table 1, we measure the precision@100 by comparing top 100 images returned using FAISS to the top 100 images ranked by L2 distance. The precision@100 is limited at 90% when compression is applied.
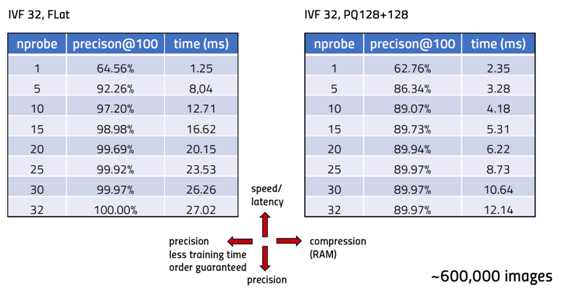
Table 1: FAISS: Index based on an inverted file (IVF) vs Index based on an inverted file with product quantization (IVF-PQ)
Another difficulty is to insert, delete, or update a single record in the FAISS index. Our catalog changes every day — new products are added, old products are retired, and new images are added for existing products. Accumulating daily changes, rebuilding, and redeploying the entire index are far from ideal solutions for a billion-item catalog that receives thousands of updates every second. To our knowledge, even Facebook did not find a better solution than daily rebuilding and redeploying.
Also, FAISS uses integers to index vectors. However, products are often indexed by strings, such as ASIN, UPC, etc. Thus, after finding products with similar images to the query image, one has to build a separate downstreaming service to map the integer ID to a string ID in order to retrieve related information, such as title, brand, and price. The separate retrieval service also leads to difficulties when adding text modifiers to visual search (a.k.a. multi-model searches), as illustrated in the situation in Figure 2.

Figure 2: Visual search in the context of text modifier
To resolve these issues, we propose an integrated text and image search based on Elasticsearch. Elasticsearch hosts its index on disk. It is an inverted-index-based search engine that uses string tokens and, therefore, does not handle L2 distance efficiently. That being said, one might ask how we were able to achieve high quality results (precision@100 > 98%) with competitive latency (<100ms). In the following sections, we’ll show how we accomplished it.
The core idea is to create text documents from image feature vectors by encoding each vector into a collection of string tokens where vectors that are close to each other will share more string tokens in common.
One method that has been used to encode vectors to strings is element-wise rounding. This strategy was first proposed and examined by Rygl et al. and Ruzicka et al. The element-wise rounding encoder rounds the top-m entries with the largest absolute value in the numerical vector to p decimal places (where p ≥ 0 is a fixed integer). It then concatenates its positional information and rounded value as the string tokens. For example,
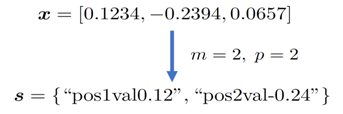
Figure 3: Element-wise Rounding
One of the drawbacks of element-wise rounding is that it tends to overlook small-magnitude entries. Those smaller values actually could play a significant role in calculating the L2 distance, thus removing them could impact performance. Moreover, it is vulnerable to data distributions. For example, when the embedding vectors are binary codes, choosing top-m entries will lead to an immediate tanglement. As a remedy, we developed a new vector to string encoding scheme called subvector-wise clustering.
The subvector-wise clustering strategy first divides the vector x ∈ R^d into m subvectors. Subvectors at the same position are considered together to be classified into k clusters. Then each subvector is encoded into a string token by combining its position in x and the cluster it belongs to, so exactly m string tokens will be produced.
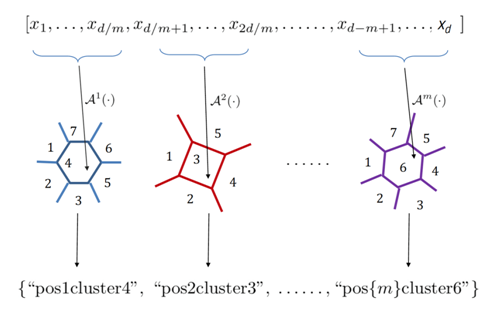
Figure 4: Subvector-wise Clustering
In contrast with the element-wise rounding encoder, the subvector-wise clustering encoder obtains m string tokens without throwing away any entry in x, and will generate string tokens more adaptive with the data distribution. As a result, it is more robust to the underlying data distribution.
If we use Google’s preLogitFlatten layer in Inception-ResNet-V2 as the representation learning model, then d = 1536, often, m = 64 or 128, and k = 128 or 256.
We found that compared to element-wise rounding, subvector-wise encoding achieves higher precision with lower latency.
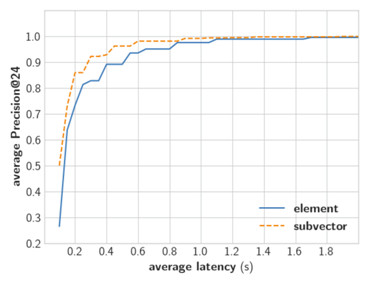
Figure 5: Pareto frontier for the element-wise rounding and the subvector-wise clustering encoders in the space of latency and precision
– Building an end-to-end visual search engine is fun!
– Elasticearch is a powerful inverted-index-based search engine.
– Subvector-wise clustering method enables Elasticsearch in finding approximate nearest neighbors.
Find more details from our [paper at SIGIR](https://sigir-ecom.github.io/ecom18Papers/paper7.pdf). Check out our [Github repository](https://github.com/gyang274/visual-search) and [Docker images](https://hub.docker.com/u/gyang274/) to deploy a fully functional visual search engine on your own with 3 lines of command:
“`
$ git clone https://github.com/gyang274/visual-search.git
$ cd visual-search
$ docker-compose up
“`
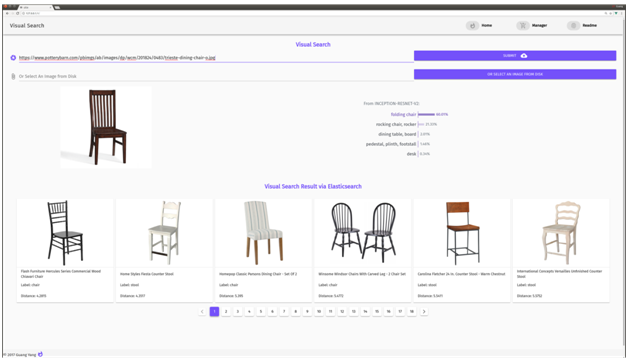
Host a fully functional visual search engine on your own — search via URL.
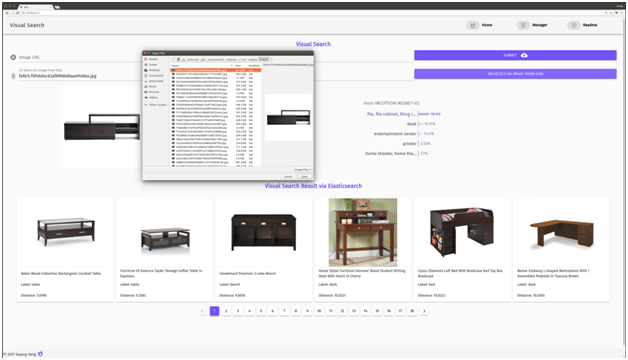
Host a fully functional visual search engine on your own — search local image.




















